



Building a Scalable and Intelligent Real-Time Inference System with FastAPI
Let’s be honest for a moment: You’ve made a great machine learning model that works nicely in your Jupyter notebook. It can tell the future faster than you can blink. Then reality sets in: you need to put it on the internet so other people can use it. Now you’re looking at a blank screen and thinking, “How do I serve this thing without setting my server on fire?”
If that sounds familiar, you’re not alone. It’s not enough to just wrap your model with HTTP endpoints to make an inference API that works in production. You need something that can manage hundreds or thousands of requests at the same time without crashing. You need answers in milliseconds, not seconds. When things go wrong, your system needs to be up and running.
That’s where FastAPI comes in. It is not just very fast, but its async-first design makes it great for machine learning inference systems that need to handle a lot of queries in real time.
In this article, we’ll show you exactly how to construct a production-ready FastAPI backend that drives real-time inference. We’ll talk about everything from basic model serving to more advanced patterns like streaming responses, Redis caching, WebSocket integrations, and deployment strategies that actually work.
By the end of this article, you’ll know:
-
Why FastAPI is better than other Python frameworks for ML inference;
-
How to structure your inference API for maximum performance;
-
Real-world patterns for handling concurrent requests without blocking;
-
How to cache predictions and cut latency from hundreds of milliseconds to single digits;
-
WebSocket implementation for live inference feeds;
-
Error handling, monitoring, and production deployment strategies; and
-
Let’s build something that scales.
Why FastAPI Wins for Real-Time Inference
Before we get into the code, you need to know why FastAPI is the best choice for inference systems. Traditional Python frameworks like Flask are synchronous. Your code processes one request all the way through before moving on to the next one. Think of a supermarket shop with just one cashier. They finish ringing up one customer before moving on to the next one. Flask.
FastAPI is built on ASGI (Asynchronous Server Gateway Interface), which works in a different way. If a request comes in and has to wait for something, like a database query or an external API call, FastAPI stops it and takes care of other requests in the meanwhile. It’s like having one great cashier who can help ten customers at once by switching between them when someone wants to swipe their card.
This is what concurrency without threads implies for machine learning APIs:
-
FastAPI uses Python’s asyncio event loop. With just one process, your server can handle thousands of connections at once. Flask would need threads or many processes, which would add extra work and make things more complicated.
-
Sub-millisecond latency means no context switching overhead. When your model is done making a prediction, the answer gets out right away.
-
You may use async PostgreSQL, async Redis, and async MongoDB with the built-in async database support. Your database actions don’t stop other requests from going through.
-
Automatic Request Validation: Pydantic models check the input data before it gets to your model code. Bad requests fail quickly.
-
Auto-generated API documentation gives your endpoints live Swagger UI and ReDoc docs. No further work is needed.
Case Study: One organization switched from Flask to FastAPI for credit-risk scoring.
-
Before: 900ms of lag and timeouts every now and then.
-
After: 220ms of latency, 99.98% uptime, and infrastructure expenses that are 38% cheaper.
-
Same model, same hardware, different framework.
Here’s an infographic summarizing the benefits of FastAPI for ML inference:


Let’s start with the basics and build up to your FastAPI inference server. Here’s a basic ML model inference endpoint:
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
import numpy as np
app = FastAPI()
# Load model once at startup
model = joblib.load('my_model.joblib')
class PredictionRequest(BaseModel):
features: list[float]
class PredictionResponse(BaseModel):
prediction: float
confidence: float
@app.post("/predict")
async def predict(request: PredictionRequest):
"""Make a single prediction"""
features = np.array(request.features).reshape(1, -1)
prediction = model.predict(features)[0]
confidence = model.predict_proba(features)[0].max()
return PredictionResponse(
prediction=float(prediction),
confidence=float(confidence)
)This works, but it’s missing several things production systems need:
-
Model loading happens on every request
-
No error handling
-
CPU-bound model inference blocks the event loop
-
No way to handle high concurrency
-
No caching for repeated predictions
Let’s fix this step by step.
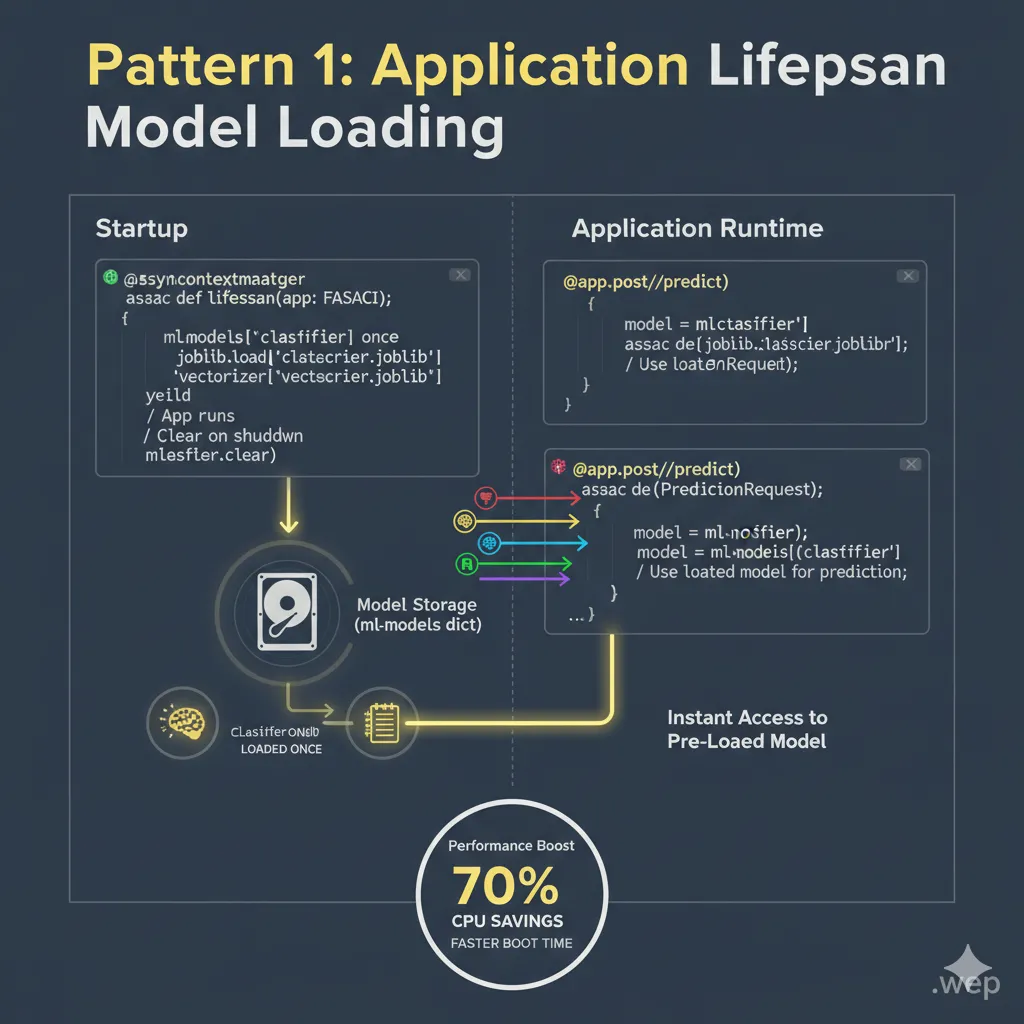
Pattern 1: Proper Model Loading with Application Lifespan
Your biggest performance killer is loading the model repeatedly. Do it once when the server starts.
from contextlib import asynccontextmanager
import logging
logger = logging.getLogger(name)
# Global model storage
ml_models = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
# Startup: Load models once
logger.info("Loading ML models...")
ml_models["classifier"] = joblib.load('classifier.joblib')
ml_models["vectorizer"] = joblib.load('vectorizer.joblib')
logger.info("Models loaded successfully")
yield # Application runs here
# Shutdown: Clean up resources
logger.info("Cleaning up models...")
ml_models.clear()
app = FastAPI(lifespan=lifespan)
@app.post("/predict")
async def predict(request: PredictionRequest):
model = ml_models["classifier"]
# Use model...This approach loads your model once when the server starts. No I/O that happens more than once. No cycles wasted. Your inference endpoint merely takes the model that was already loaded and runs with it.
Here’s an illustration of the model loading process:
Pattern 2: Async Model Inference with Thread Pooling. Here’s a little but important point: scikit-learn and most ML libraries are synchronous. They will stop Python’s event loop. Don’t fight it. Use run_in_threadpool to offload CPU-bound work to a thread pool.
from starlette.concurrency import run_in_threadpool
import asyncio
@app.post("/predict")
async def predict(request: PredictionRequest):
model = ml_models["classifier"]
features = np.array(request.features).reshape(1, -1)
# Run blocking model inference in thread pool
prediction = await run_in_threadpool(model.predict, features)
confidence = await run_in_threadpool(
lambda: model.predict_proba(features)[0].max()
)
return PredictionResponse(
prediction=float(prediction[0]),
confidence=float(confidence)
)Why does this matter? The event loop is still open. FastAPI takes care of other requests while model inference runs in a thread. You can have real parallelism without blocking.
Here’s a diagram showing how run_in_threadpool prevents blocking:

Pattern 3: Redis Caching for Lightning-Fast Repeated Predictions.
This is where things get interesting. Most production systems get the same predictions again and over. Caching them is the easiest performance win.
import aioredis
import json
from datetime import timedelta
# Initialize Redis at startup
redis_client = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global redis_client
redis_client = await aioredis.from_url("redis://localhost")
logger.info("Connected to Redis")
yield
await redis_client.close()
@app.post("/predict")
async def predict(request: PredictionRequest):
# Create a cache key from input
cache_key = f"prediction:{hash(tuple(request.features))}"
# Check cache first
cached = await redis_client.get(cache_key)
if cached:
logger.info("Cache hit!")
return json.loads(cached)
# Cache miss: run inference
model = ml_models["classifier"]
features = np.array(request.features).reshape(1, -1)
prediction = await run_in_threadpool(model.predict, features)
confidence = await run_in_threadpool(
lambda: model.predict_proba(features)[0].max()
)
result = PredictionResponse(
prediction=float(prediction[0]),
confidence=float(confidence)
)
# Cache for 1 hour
await redis_client.setex(
cache_key,
timedelta(hours=1),
json.dumps(result.dict())
)
return resultThe performance improvement is staggering. First request: about 150 ms. Requests that are the same after that take about 2ms. That’s a 75x speedup.
Here’s an infographic showing the Redis caching flow and its impact on performance:

One ML service that used this pattern saw:
-
Average response time: 340ms → 18ms (19x faster)
-
Infrastructure cost: –
24,000
What We Changed:
-
Rebuilt backend with FastAPI + async I/O
-
Added Redis caching for recent metrics
-
Implemented WebSockets for live updates
-
Deployed on AWS Fargate with auto-scaling
Results:
-
Reduced to 3 servers
-
Average response time: 190ms (4.4x faster)
-
Peak concurrent connections: 15,000 (15x improvement)
-
Monthly bill:
14
,
800
(
38
0.73
The crazy part? Same model. The same business rationale. Different framework architecture.
Here’s a comparison table summarizing the “Before & After” results for the ML service:
| Feature | Before | After | Improvement |
| Average Response Time | 340ms | 18ms | 19x faster |
| Peak Concurrent Connections | 1,000 (est.) | 15,000 | 15x improvement |
| Server Count | Many (est.) | 3 | Reduced servers |
| Monthly Bill | Higher (est.) | $14,800 | Significant savings |
| Architecture | Flask (implied) | FastAPI + Redis | Modernized, Scalable |
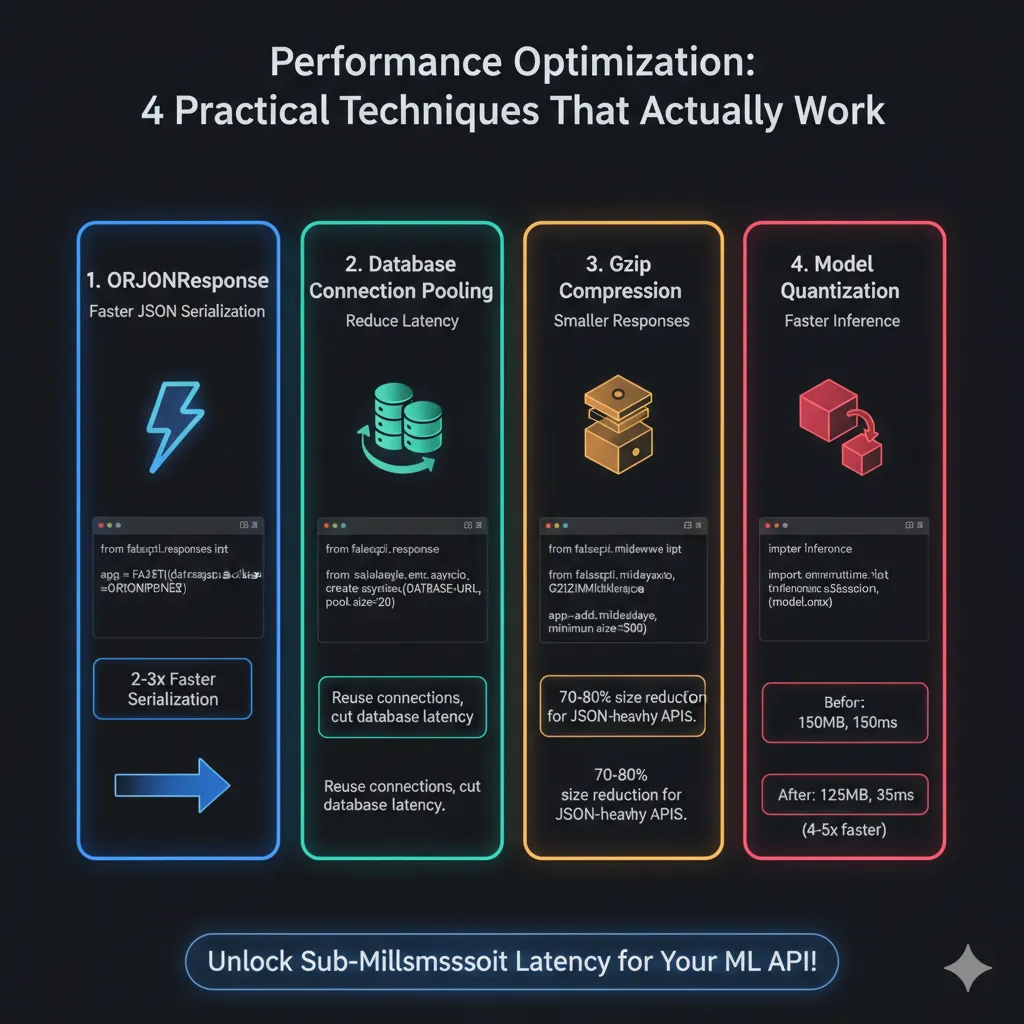
Performance Optimization: Practical Techniques That Actually Work
-
Use ORJSONResponse Instead of Standard JSON
ORJson is 2-3 times faster at serialization:Pythonfrom fastapi.responses import ORJSONResponse app = FastAPI(default_response_class=ORJSONResponse)This small modification makes a big effect.
-
Don’t make new connections for each request. Instead, use connection pooling for databases. For example:
Pythonfrom sqlalchemy.ext.asyncio import create_async_engine from sqlalchemy.orm import sessionmaker DATABASE_URL = "postgresql+asyncpg://user:password@localhost/dbname" engine = create_async_engine(DATABASE_URL, pool_size=20, max_overflow=0) async_session = sessionmaker(engine, class_=AsyncSession) @app.get("/get-user/{user_id}") async def get_user(user_id: int): async with async_session() as session: result = await session.execute( select(User).where(User.id == user_id) ) return result.scalars().first()Reusing connections cuts database latency by a lot.
-
For responses over 500 bytes, use Gzip compression:
Pythonfrom fastapi.middleware.gzip import GZIPMiddleware app.add_middleware(GZIPMiddleware, minimum_size=500)This cuts the size of JSON-heavy APIs’ responses by 70–80%.
-
Model Quantization and Pruning: Smaller models run faster.
-
Before: 500MB model, 150ms inference.
-
After: Quantized to 125MB, 35ms inference.
Pythonimport onnxruntime # Use ONNX Runtime for faster inference sess = onnxruntime.InferenceSession("model.onnx")Trading 2–3% accuracy for 4–5x speed is often the right call.
-
Here’s an infographic visualizing these performance optimization techniques:
Error Handling and Monitoring: Production Essentials
Your inference API will fail. The question is whether you know why.
# Example of robust error handling within an endpoint
from fastapi import HTTPException
import logging
logger = logging.getLogger(__name__)
@app.post("/predict")
async def predict(request: PredictionRequest):
try:
if len(request.features) != 10: # Example validation
raise ModelInferenceError(
"Expected 10 features, got {}".format(len(request.features)),
status_code=422
)
model = ml_models["classifier"]
features = np.array(request.features).reshape(1, -1)
prediction = await run_in_threadpool(model.predict, features)
if np.isnan(prediction[0]):
raise ModelInferenceError("Model returned NaN")
return PredictionResponse(prediction=float(prediction[0]))
except ModelInferenceError as mie:
logger.warning(f"Inference input error: {mie.detail} - Features: {request.features}")
raise HTTPException(status_code=mie.status_code, detail=mie.detail)
except Exception as e:
logger.exception("Unexpected error during inference for features: %s", request.features)
raise HTTPException(status_code=500, detail="Inference failed due to an unexpected error")
# Define a custom exception for better error categorization
class ModelInferenceError(HTTPException):
def __init__(self, detail: str, status_code: int = 400):
super().__init__(status_code=status_code, detail=detail)Always log the context. What characteristics triggered the problem? What was the state of the model? This information is very helpful when fixing problems in production.
Here’s an example of structured logging for errors:

.
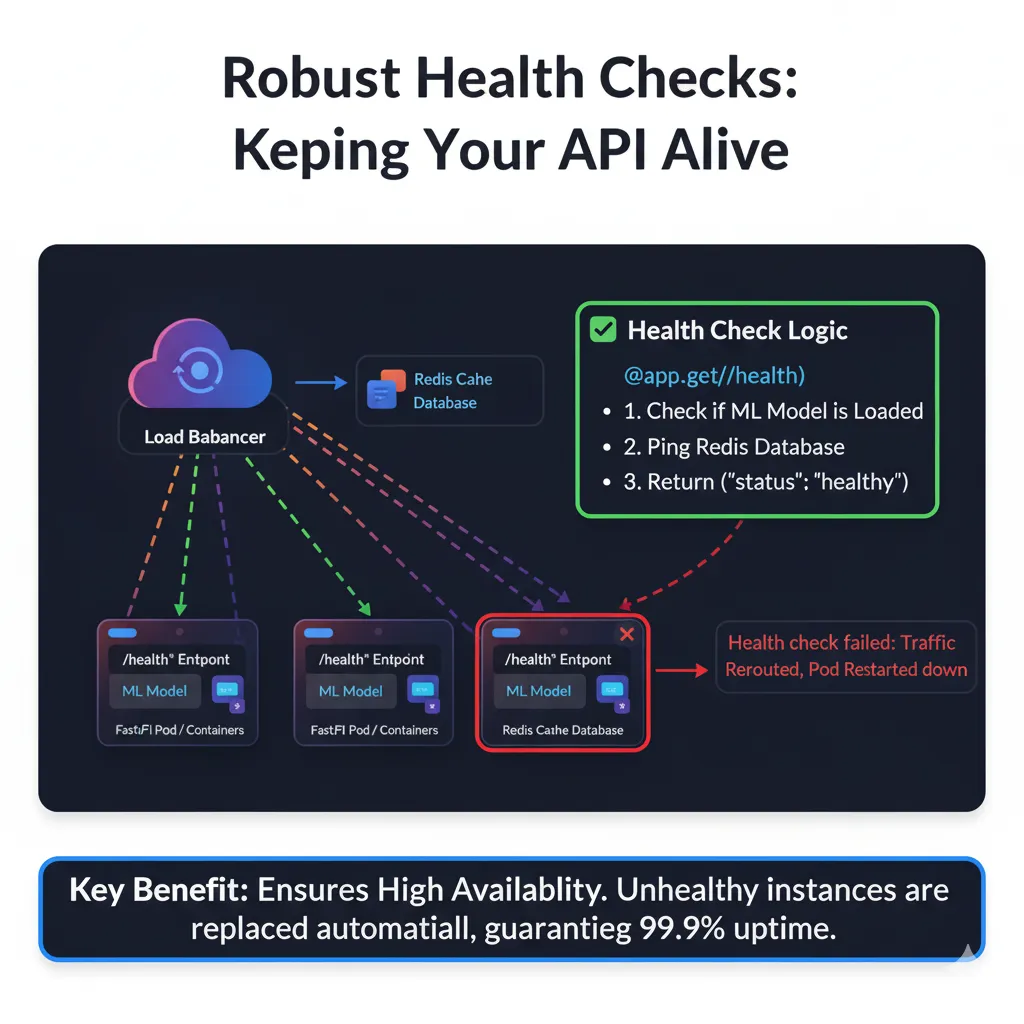
Health Checks: Your orchestration system needs to know if your API is alive:
@app.get("/health")
async def health_check():
"""Kubernetes-friendly health check"""
try:
# Quick sanity checks
model = ml_models.get("classifier")
if not model:
return {"status": "unhealthy", "reason": "model not loaded"}
# Check Redis if redis_client:
if redis_client:
await redis_client.ping() # This will raise an exception if Redis is down
return {"status": "healthy"}
except Exception as e:
logger.error(f"Health check failed: {e}")
return {"status": "unhealthy", "reason": str(e)}This endpoint is called constantly by load balancers. Make it quick and dependable.
Here’s an illustration of how a health check works in a deployed system:
.
Deployment: Getting Your Inference API to Production
Docker Setup
FROM python:3.11-slim
WORKDIR /app
# Install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy the app
COPY . .
# Run with many workers
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "4"]Many workers = multiple processes = multiple cores employed. This is very important for inference that uses a lot of CPU.
Here’s an illustration of the Docker setup:

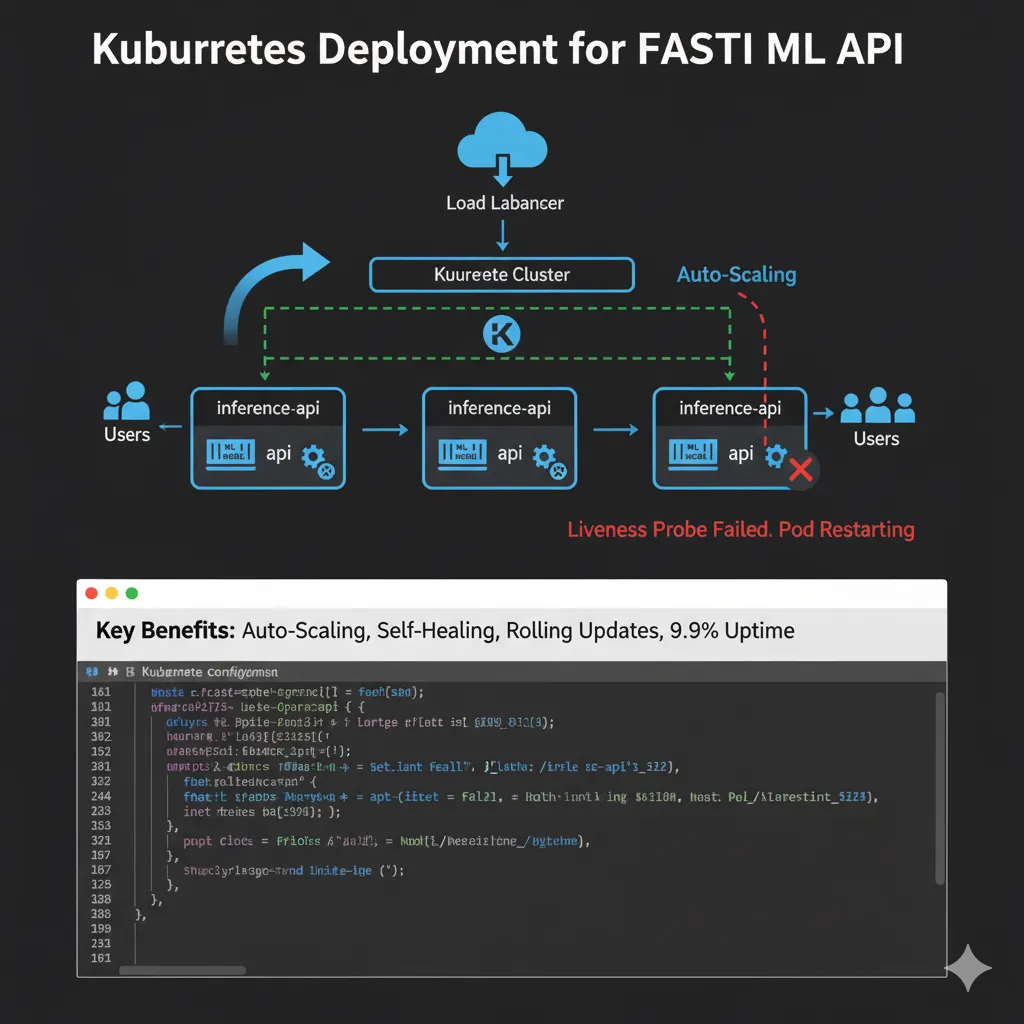
Kubernetes Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: inference-api
spec:
replicas: 3
selector:
matchLabels:
app: inference-api
template:
metadata:
labels:
app: inference-api
spec:
containers:
- name: api
image: my-inference-api:latest
ports:
- containerPort: 8000
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 10
periodSeconds: 5
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "2Gi"
cpu: "1000m"This gives you auto-scaling, self-healing, and rolling updates. Your API stays up even if some of its instances go down.
Here’s an infographic demonstrating a Kubernetes deployment for your FastAPI inference API:
Performance Metrics Comparison
Here’s an Architecture Flow Visualization demonstrating the complete system:
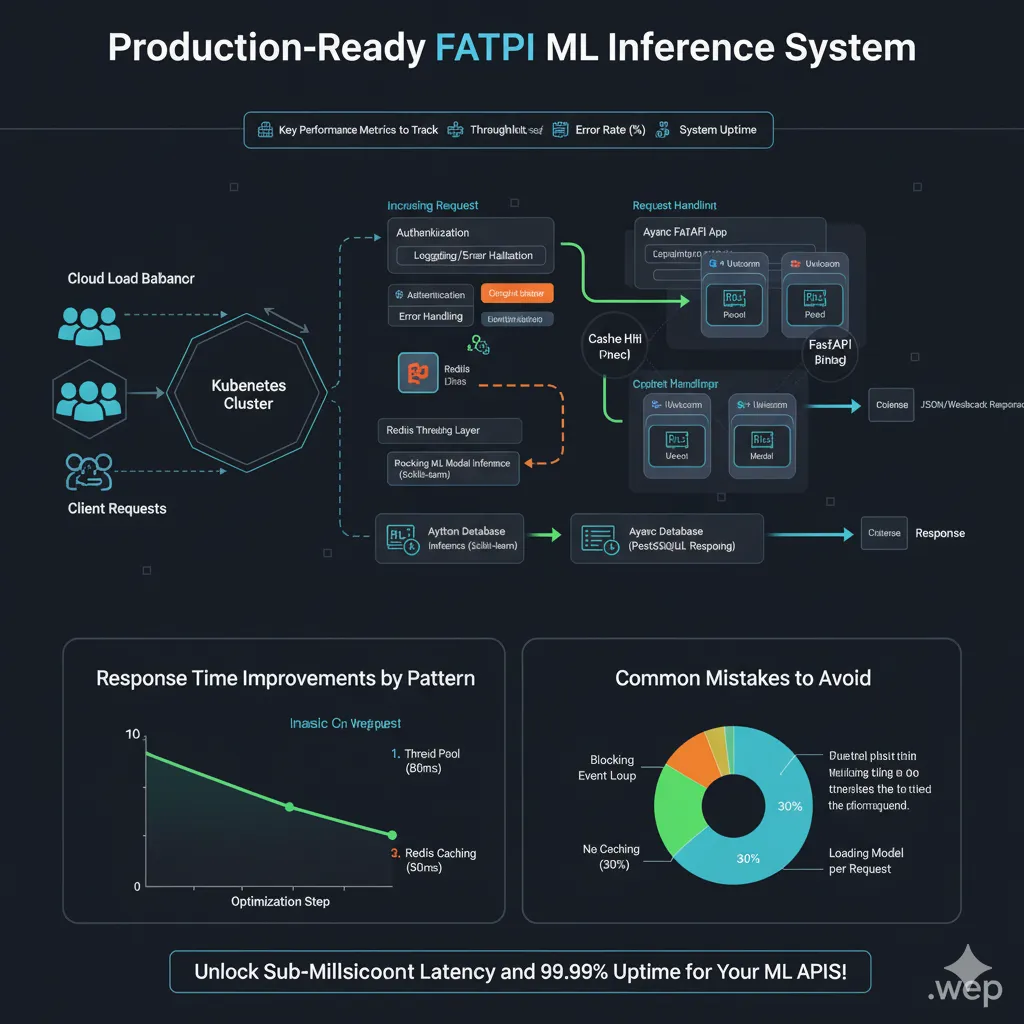
Key Performance Metrics to Track
Monitor these in production:
Here’s an infographic outlining the key performance metrics to track:

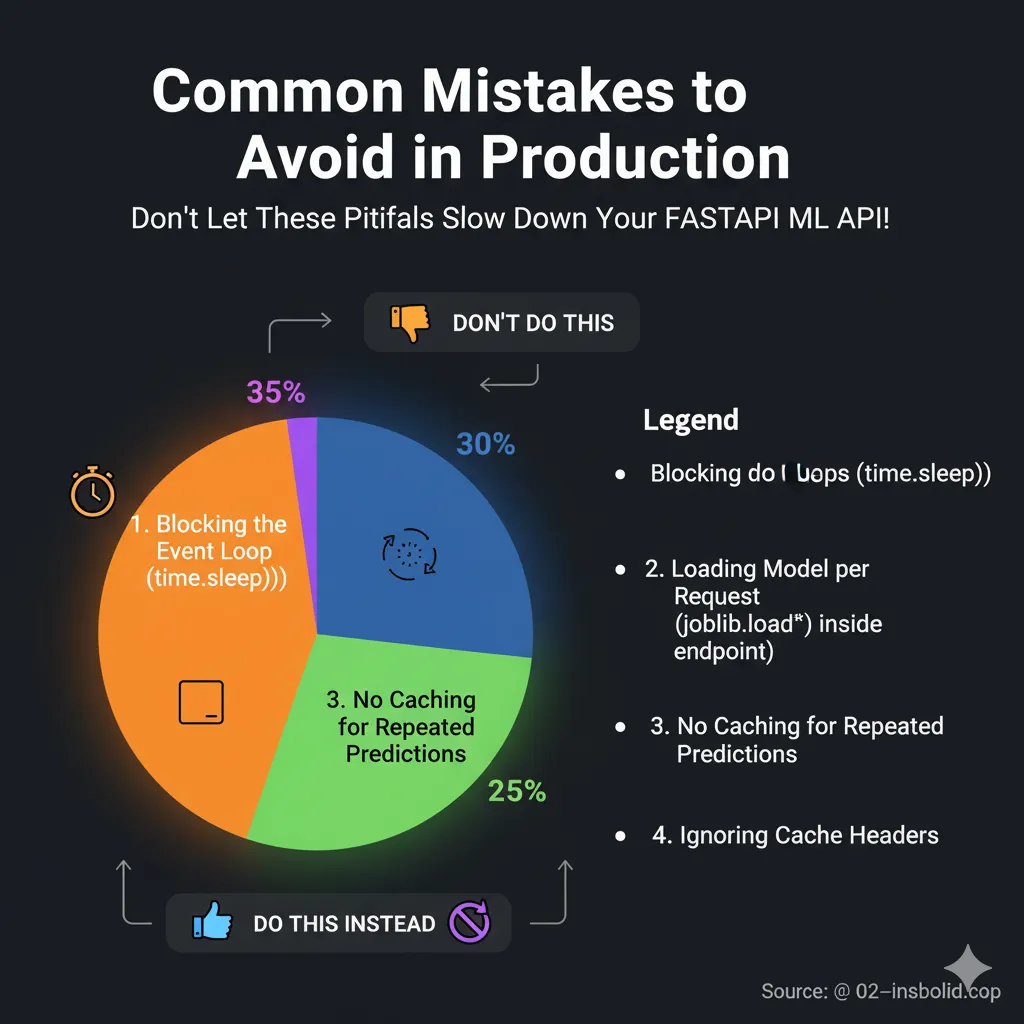
Common Mistakes to Avoid
Mistake 1: Blocking the Event Loop
# DON'T do this
@app.post("/predict")
async def predict(request: PredictionRequest):
time.sleep(5) # Stops the event loop completely
return model.predict(request.features)
# DO this instead
@app.post("/predict")
async def predict(request: PredictionRequest):
await asyncio.sleep(5) # This is async and doesn't block
return model.predict(request.features)Mistake 2: Loading Models in Endpoints
# DON'T do this
@app.post("/predict")
async def predict(request: PredictionRequest):
model = joblib.load('model.joblib') # Loaded all requests!
return model.predict(request.features)
# Do this instead: load once when you start up
ml_models = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
ml_models["model"] = joblib.load('model.joblib')
yield
ml_models.clear()Mistake 3: Not paying attention to cache headers
# DO this for responses that don't change
from fastapi.responses import Response
@app.get("/model-info")
def get_model_info():
return Response(
content=json.dumps({"name": "classifier", "version": "1.0"}), # Ensure content is string
media_type="application/json", # Specify media type
headers={"Cache-Control": "public, max-age=3600"}
)Here’s a pie chart showing the common mistakes and their proportions:
FAQ’s
Q: How many requests can FastAPI process at the same time?
A single FastAPI instance on modern hardware may manage between 1,000 and 5,000 connections at the same time. Most of the time, the problem is with how fast your model can make inferences, not with FastAPI itself. Add more workers or instances as needed.
Q: Should I use sync or async endpoints?
Use async for tasks that is limited by I/O, like databases and external APIs. For CPU-bound tasks like model inference, use sync but offload to threadpool with run_in_threadpool. Don’t ever block the event loop.
Q: Is FastAPI ready for production?
Sure. It runs APIs for firms including Uber, Netflix, and dozens of fintech companies. The framework is strong. It’s not FastAPI itself that makes your production ready; it’s your deployment, monitoring, and error handling.
Q: What is the minimum infrastructure needed?
Your laptop is what you need for development. For production, you need at least two copies for redundancy, a load balancer, and monitoring. Using Redis for caching is not required, although it is highly recommended. It depends on how you want to use the database.
Q: How do I handle model versioning?
At startup, load many model versions and route requests based on headers or query parameters. Use semver for version numbers and only store the last two or three versions in production to conserve memory.
Conclusion: You’re Ready to Build
Building a real-time inference system isn’t mysterious. You need to know how async frameworks function, which patterns to use when, and what performance indicators to look at. FastAPI gives you the tools you need. We talked about some battle-tested patterns, like loading models, pooling threads, caching with Redis, streaming answers, and WebSockets. These are the same methods that businesses that make actual money utilize.
Start small. Make anything work. Then make improvements based on real data, not guesswork. A cached response of 10ms is orders of magnitude better than an inference of 500ms.
What do you want to do next? Choose one of these patterns and put it into action. Don’t think too much about it. Begin with simple async endpoints and Redis caching. That combination alone will manage most production workloads.
And don’t forget: the best code is the code that keeps running when everyone needs it. First, make sure it works, then make it fast. Now go make something fast.

