
Case Study: How to Avoid a Biased AI Going Wrong
When we think about AI, we often picture a future where everything is fairer than it is now. Algorithms that make decisions without the biases and prejudices that affect human judgment. But the truth is that things are much more complicated.
Over the last ten years, we’ve seen a worrying trend: AI systems made to help people make better decisions in healthcare, criminal justice, hiring, and law enforcement have consistently repeated, amplified, and scaled human biases, with terrible effects in the real world. This isn’t just a problem that academics talk about in their papers. It’s a crisis that millions of people are going through right now.
For the past few months, I’ve been looking into big AI bias cases, talking to researchers, and looking at ways to fix the problem. What I’ve learned is both sad and hopeful. Algorithmic bias seems almost unavoidable because of how AI systems are trained, but the way forward is clear—if companies are brave enough to do it.
The Size of the Problem: Getting to Know AI Bias
Before we look at specific cases, we need to know what AI bias is and why it happens. AI bias isn’t “bad” intent; it’s an error in the results of machine learning that comes from biased assumptions in the training data, bad algorithm design, or how we define the problem itself.
Bias is a sneaky process: biased data trains biased models, which make biased decisions on a large scale, affecting millions of people at once in ways that are often hidden until a lawsuit or media investigation brings them to light.
The numbers are very clear:
According to research from USC’s Information Sciences Institute, between 3.4% and 38.6% of the data in widely used AI training datasets is biased, depending on which database we look at.
When we think about how much more accurate facial recognition is for light-skinned males than for dark-skinned females, we see that there is a 34-fold difference.
At the same time, 51% of Americans think that AI will make healthcare less biased against people of color and different ethnicities. This shows a dangerous gap between what people think and what is true.
The most frightening thing is that algorithms don’t just copy human bias; they make it worse. One study at USC found that “this biased data tends to be amplified, because the algorithm is trying to think like us and predict the intent behind the thought.” Bias isn’t just a problem; it gets worse and worse.
Case 1: The Healthcare Algorithm That Picked Healthier White Patients
One of the most important cases of AI bias in recent history happened quietly in hospitals all over the United States. A popular healthcare algorithm made medical decisions for more than 100 million U.S. patients between 2014 and 2019. It was easy for it to do its job: figure out which patients needed intensive care management.
It seemed like an objective way to do things: look at how much money people spend on healthcare to figure out who would benefit the most from intervention.
The algorithm didn’t work at all, but it wasn’t clear how. Researchers from UC Berkeley and the University of Chicago, led by Ziad Obermeyer, published their results in the journal Science in 2019. The algorithm was consistently sending care to White patients while ignoring Black patients who needed it much more.
The Mechanism of Bias
The bias worked this way: the algorithm used the cost of healthcare as a stand-in for health needs. But because of structural racism in American healthcare, Black patients with the same health problems pay less than White patients because they have historically had less access to care and treatment. So, the algorithm figured out that Black patients were “less sick” at any price point. A Black patient needed to have much worse symptoms before the algorithm’s risk score would automatically enroll them in the care management program.
The numbers were horrible. When researchers fixed the algorithm to take these differences into account, the impact was massive:
| Metric | Original Algorithm | Fixed Algorithm |
| Black patients automatically enrolled in critical care | 18% | 47% (nearly 3x increase) |
The bias in this algorithm made it so that more than half of the Black patients who needed extra care were not found in all the hospitals that used it. This wasn’t a case where someone coded discrimination on purpose. Instead, the team built a technically sound system without questioning a basic assumption: that healthcare spending accurately reflects healthcare needs.
Case 2: The COMPAS Algorithm and Digital Criminal Justice
The healthcare case shows bias through proxy variables, while the COMPAS story shows bias in the data itself. COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) is a risk assessment algorithm that courts in the United States use to figure out how likely it is that a defendant will commit another crime. It affected decisions about sentencing, parole hearings, and bail for more than ten years, literally controlling freedom and imprisonment.
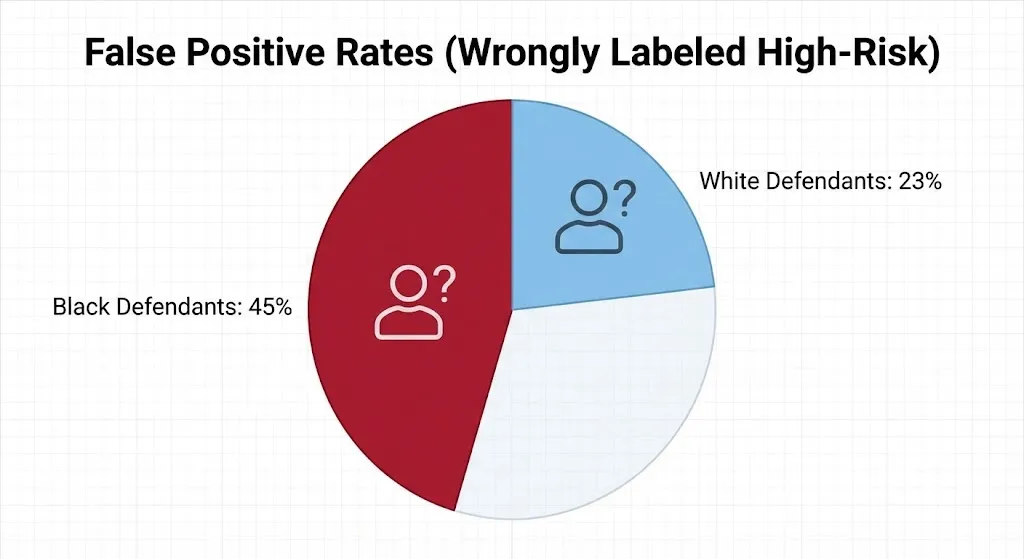
ProPublica’s investigative journalism in 2016 uncovered a terrible racial bias. The algorithm was much more likely to wrongly label Black defendants as high-risk than White defendants.
Black defendants were wrongly labeled as high-risk 45% of the time, while White defendants were only 23% of the time.
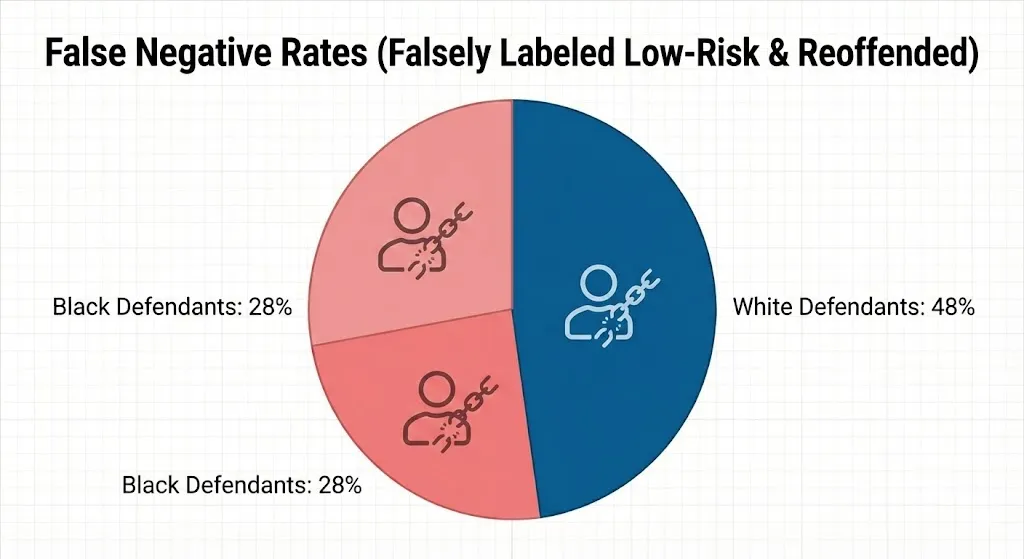
When it came to false negatives, the pattern changed: 48% of White defendants were falsely labeled as low-risk and then reoffended, while only 28% of Black defendants were.
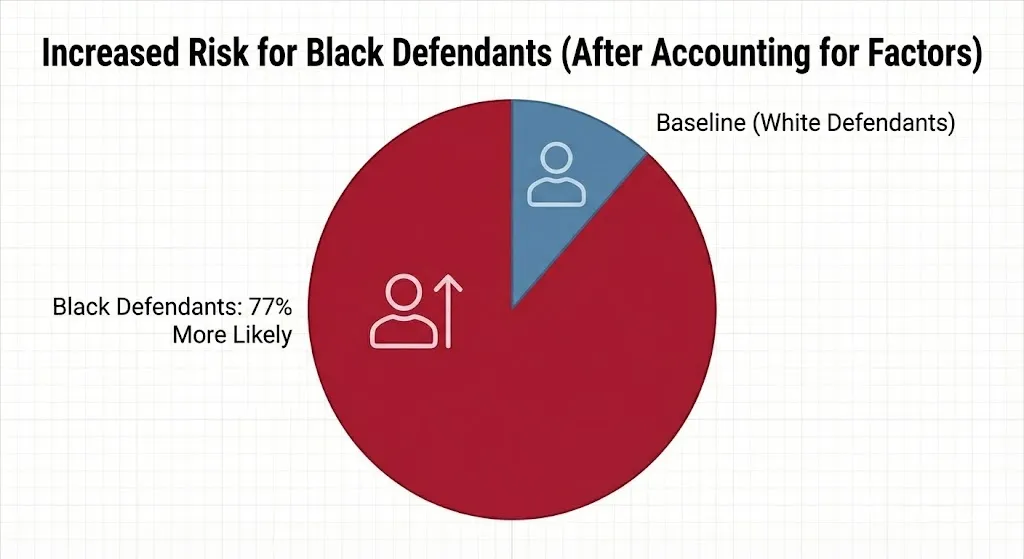
When researchers took into account other factors like previous crimes, age, and gender, Black defendants were still 77% more likely to be seen as higher risk than White defendants in the same situation.
The issue stemmed from historical bias present in the training data. The algorithm learned from decades of criminal justice records that showed systemic racial differences in policing, prosecution, and sentencing, not differences in actual rates of reoffending. COMPAS kept and made that injustice worse on a large scale by treating historical data as objective truth.
Case 3: Face Recognition and the First Wrongful Arrest
People are interested in bias in facial recognition because they can see it, literally. Joy Buolamwini’s groundbreaking research at MIT found that identification errors for lighter-skinned men never went above 1%, but for darker-skinned people, they went up to 20%. Worse, women with darker skin had 34% more mistakes than men with lighter skin. These weren’t just theoretical harms.
In January 2020, Robert Williams, an African American auto shop worker from Detroit, was arrested outside his home in Farmington Hills, Michigan, in front of his two young daughters and wife. The arrest was based on a false facial recognition match. The police used Amazon Rekognition to look at video from a robbery that happened in 2018. The algorithm said that his driver’s license picture was a match. Police arrested him without checking any further. He spent 30 hours in a dirty, overcrowded cell before the charges were dropped. This was the first time that facial recognition bias was publicly reported to have led to an incorrect arrest.
Williams’ case wasn’t the only one. In 2023, the ACLU used Amazon Rekognition to compare a database of 25,000 mugshots to pictures of all current members of Congress. The results were shocking: the system wrongly linked 28 members of Congress to people suspected of crimes. Almost 40% of these wrong matches were people of color, even though people of color only make up 20% of Congress.
Case 4: The Amazon Hiring Algorithm That Hurt Women
A group of machine learning experts at Amazon’s Edinburgh engineering center were working on the future of hiring: an AI system that could automatically search the internet for good job candidates and rate applicants.
By 2015, the team saw a problem: the algorithm didn’t like women. It had been trained on ten years’ worth of Amazon’s hiring data, which showed how badly the tech industry was skewed toward men (about 10% of technical jobs went to women). The algorithm learned this pattern and used it as a fact about who should get the job.
It systematically lowered the ranking of resumes that had the word “women” in them, like “women’s chess club,” because it thought that women who did things were less likely to get hired. Amazon’s system had automated sexism. When the company saw the problem, they decided to cancel the project instead of trying to fix it.
The same thing has happened in the hiring industry since then. The University of Washington found that AI screening systems favored white applicants 85% of the time over equally qualified Black applicants in 2025.
Case 5: Dermatology AI and Missing Melanoma
Medical AI is biased in more ways than just predicting risks. AI systems trained to find skin cancer do a lot worse on darker skin tones.
Melanoma is more common in people with lighter skin because they are more exposed to UV light. However, Black patients who get melanoma often have more advanced disease and lower survival rates. This difference is partly because people can’t see dermatologists as often and get diagnosed later—a health equity issue that biased AI makes worse.
Research indicates that AI models for early melanoma detection are primarily trained on individuals with lighter skin types.
If caught early, the 5-year survival rate for early-stage melanoma is about 99%.
If the cancer has spread, the rate drops to only 35%.
An AI system that doesn’t work well on dark skin doesn’t just make a mistake; it could kill people.
What Causes AI Bias? The Main Causes
To stop bias, you need to know where it comes from. I’ve found a few sources that are all connected:
Training Data that is Unfair or Unbalanced: This is the main problem. If the data doesn’t include enough people from certain groups or if it shows discrimination in the past, the model will copy those patterns.
Hidden Assumptions and Proxy Variables: The healthcare algorithm case is a great example of this. When you use healthcare spending as a proxy for health needs, you make an assumption. If that assumption is indicative of structural inequity, bias ensues automatically.
Cultural and Institutional Blind Spots: Homogeneous development teams frequently overlook biases that would be evident to individuals from the impacted community.
Mistakes in Measurement and Unfair Labels: If people who label training data are biased, those biases become part of the data itself.
Amplification by Algorithms: Even when the training data is fairly balanced, algorithms can make bias worse by giving too much weight to features related to race or gender to find predictive patterns.
How to Make Fair AI Systems: Mitigation Strategies
The good news is that we know how to make AI less biased. It takes discipline, but it is possible. Here are the best ways to do it:
Preprocessing and Auditing Data (75% Effective)
Checking datasets for demographic imbalances and missing features regularly.
Using fairness metrics like equalized odds and demographic parity to measure bias.
Using preprocessing methods like resampling and reweighting to ensure equal representation.
Taking out or lowering the priority of proxy variables related to protected traits.
Algorithmic Adjustments and Fairness-Aware Algorithms (Effectiveness: 70%-78%)
Use fairness constraints during model training to ensure fair results for all groups.
Use explainable AI methods to figure out why an algorithm makes certain choices.
Use post-processing techniques to change the outputs and fix differences after predictions are made.
- Diverse Development Teams (80% Effective)
This is the best way to reduce the risk. Diverse teams offer different points of view regarding race, gender, disability status, and cultural background. When a team that doesn’t include women makes an AI hiring tool, no one asks if the system might be unfair to pregnant women.
- Transparency and Explainability (Effectiveness: 65%)
Transparency helps stakeholders learn how a system works, gives affected communities a chance to fight unfair results, and makes developers responsible. When companies hide how their algorithms work (“black box” algorithms), bias can last for years.
- Continuous Monitoring and Auditing (Effectiveness: 72%)
AI systems won’t stay fair over time. Data distributions change. You must regularly check accuracy for different groups and track differences in real-world outcomes.
- Structures for Governance and Accountability
Set up an AI ethics board, establish approval gates so models can’t go into production without fairness checks, and keep track of all decisions for auditing.
Putting It Into Practice: Creating Responsible AI
We aren’t starting from scratch. Leading organizations and frameworks give us a plan:
Principles for AI from the OECD: Adopted by over 46 countries, encouraging openness, clarity, strong safety measures, and responsibility.
The EU AI Act: Going into effect in 2024, this bans AI uses that go against EU values (like social scoring) and requires providers of high-risk AI systems to register their systems and get certification.
The NIST AI Risk Management Framework: Defines four main functions: Govern, Map, Measure, and Manage, to make fair AI practical.
Microsoft Responsible AI Standard (2024 Update): Includes six principles: fairness, reliability, privacy, inclusiveness, transparency, and accountability.
What to Do Next: Regulatory Action
We’re starting a new time when AI will be held responsible. There were 59 new rules about AI in 2024, more than twice as many as in 2023.
More importantly, courts are starting to see that algorithms are covered by anti-discrimination law. The 2025 Workday ruling said that employers can’t avoid being sued for civil rights violations by saying that a computer made the decision. This legal precedent changes everything: using biased AI now comes with real legal and financial risks.
At the same time, leaders are putting money into research. Microsoft said that by making changes to its algorithm, it was able to cut the number of mistakes made when recognizing the faces of dark-skinned women by up to 20 times. These changes are huge.
The Moral Necessity: Why This Is Important Beyond Rules
I want to be clear: we need to fix AI bias not because of lawsuits or rules, but because the other option is not acceptable. A Black patient refused important medical care. An innocent man arrested and jailed. A qualified woman turned down for a job. These are happening to real people right now.
“Algorithms can do terrible things, or algorithms can do wonderful things. Which one of those things they do is basically up to us.”
— Ziad Obermeyer, Researcher
The data we choose, the variables we prioritize, and the metrics we optimize for all affect whether an algorithm will be a tool for fairness or discrimination. The good news is that we have power. We can ask for fairness audits, ensure diverse teams build these systems, and build AI where fairness is a priority, not an afterthought.
Questions People Often Ask
Q1: How do I know if the AI system I’m using is unfair?
Look for openness. Does the business explain how the algorithm works? Do they tell you how accurate their results are for different groups of people? Do they have a way for people to appeal decisions? If they’re not being honest about how the system works, that’s a bad sign. Request the results of a fairness audit.
Q2: Is it possible for AI to never be biased?
No. All AI systems show the choices, assumptions, and data used to train them. But strict processes can help measure, reduce, and lessen bias a lot. The goal isn’t to be perfect; it’s to use it responsibly and always try to do less harm.
Q3: If AI makes a biased choice, who is to blame: the company, the developer, or the algorithm?
The company that puts the system in place is legally and morally responsible. The Workday ruling from 2025 made it clear that you can’t let an algorithm take care of your responsibilities.
Q4: What can people do to support AI that is fair?
Help with rules at the local and national levels. Talk to companies about how they test for fairness. If you think an algorithmic decision is unfair to you, fight it by filing complaints.
Q5: Have any AI systems been able to successfully cut down on bias?
Yes. Microsoft’s changes to facial recognition cut mistakes for dark-skinned women by 20 times. Researchers at UC Berkeley found that retraining healthcare algorithms with better variables doubled the number of Black patients identified as needing care. It shows that it’s possible.
In Conclusion, We All Have a Part to Play
The problems with COMPAS, healthcare algorithms, facial recognition, and biased hiring tools aren’t just mistakes or one-time events. They’re the expected results of a development process that doesn’t put fairness first from the start.
We are at a turning point. The choices we make about how to build, use, and regulate AI in the next few years will determine whether this technology is used to promote fairness or to make unfairness worse. The only thing left is the desire to act. We need to question our assumptions, make sure our data is accurate, and promise to keep getting better.
It means realizing that being efficient isn’t enough; fairness is not up for debate. People like Robert Williams are counting on us to do this right.

