
Introduction
How Do Transformers Work In AI ? The Game-Changing Innovation: The thing about transformers is as follows: they have entirely changed the game when it comes to artificial intelligence. Prior to the advent of transformers in 2017, AI models would resemble such a friend who has to listen to all the details of a story in chronological sequence. They consumed information one word at a time, and that was agonizingly slow, not taking into consideration the bigger picture.
The advent of transformers altered all these by implementing the self-attention mechanisms. Imagine it as being able to perceive the context and the relationship between all the words in a sentence and all those in one instant. It is akin to reading a book line by line as compared to having the ability to read whole paragraphs at the same time.
In principle, the transformer model is a deep learning model that converts input sequences into output sequences. What is special about it, though, is the process by which it achieves this transformation – through attention mechanisms that are capable of determining the most significant elements of the input as to the creation of each element of the output.
The Attention Revolution: Why “Attention Is All You Need”
The article announcing the breakthrough of transformers was entitled in an insubordinate manner: “Attention Is All You Need.” The Google researchers were not merely being clever, but they were making a big statement. They demonstrated that it was possible to create incredibly powerful language models without the use of the standard recurrent neural networks (RNNs) and convolutional neural networks (CNNs).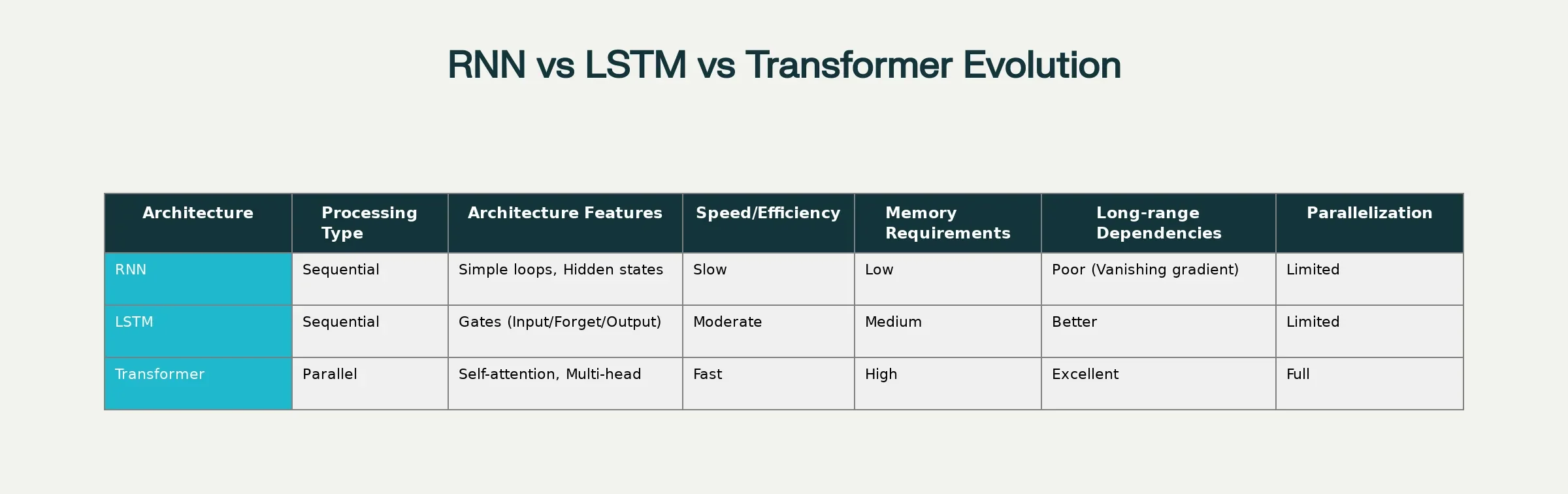
Evolution from Traditional Sequential Models to Transformer Architecture
The secret sauce is self-attention. This is how it functions in a simplile, in the phrase “The animal didn’t cross the street because it was too tired,” the mechanism of self-attention assists the model to determine that “it” pertains to the animal, rather than the street. This contextual comprehension occurs to each and every word, at a time.
Mathematically, it is the scaled dot-product attention equation, a mathematical masterpiece:
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})VWhere Q (Query), K (Key), and V (Value) matrices collaborate to find out which components of the input sequence should be given attention.
Traditional sequential models have been replaced by transformer architecture by evolution.
Decomposing the Transformer Architecture.
It is time to get our hands dirty and find out exactly how transformers work under the hood. The architecture may appear complicated initially, but after knowing its fundamental elements, it is actually very beautiful.
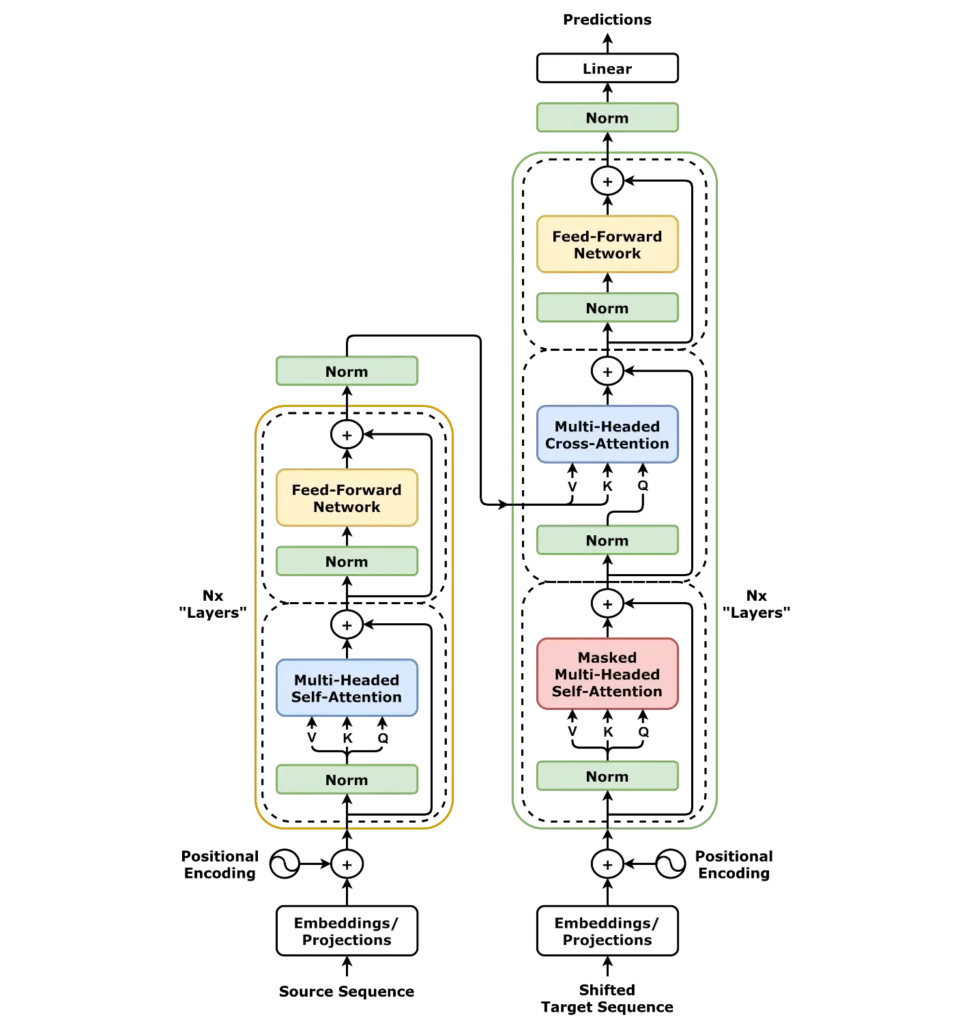
Source – Wikipedia
Flow of Transformer Architecture: Between the input and the output.
Input Embedding: Words to Numbers.
All this begins with input embedding. Translators cannot operate with plain text; they require numbers. Every word is transformed into a high-dimensional vector (usually 512 or 768 dimensions), which represents its semantic meaning. It is as though providing every word a mathematical fingerprint.
Positional Encoding: Chaos to Order Teaching.
This is where the interesting part comes in. Transformers operate concurrently, unlike RNNs, which understand sequence order. But how do they know that “the cat sat on the mat” is not the same thing as “the mat sat on the cat”?
Enter positional encoding. This trick provides position information to every word embedding with the help of sine and cosine functions:
PE(pos,2i)=sin(pos100002i/dmodel)PE_{(pos,2i)} = \sin(\frac{pos}{10000^{2i/d_{model}}})PE(pos,2i+1)=cos(pos100002i/dmodel)PE_{(pos,2i+1)} = \cos(\frac{pos}{10000^{2i/d_{model}}})The mathematical patterns make each position to have a different signature, and therefore the model can learn the order of the words.
Multi-Head Attention: The Star of the Show.
It is the magic that occurs here. Multi-head attention does not examine words as a one-way flow; it examines the relationships in many different ways at the same time.
Suppose you are reading the sentence: “the bank by the river.” One head of attention may be the financial definition of the word “bank,” whilst another may have the geographical context. The model represents various types of relationships by having several heads (usually 8 or 12).
Feed-Forward Networks: Introducing Non-Linearity.
Once the information has been attended to, it is sent through feed-forward neural networks. These layers make the model non-linear and add complexity, which assists in learning complex patterns. Consider them as processing units that refine and improve the attention outputs.
Layer Normalisation and Residual Connections.
Transformers apply residual connections and layer normalisation to maintain a stable and effective training. Such methods aid in the smooth flow of information across the network and avoid the fear of a vanishing gradient problem that was experienced in the earlier architectures.
Encoder vs. Decoder: The Two Aspects of Transformers.
The original transformer architecture has two components:
Encoder: Processes input sequence and comprehends. Such models as BERT make use of just the encoder part and are useful in such tasks as text classification and question answering.
Decoder: Produces output sequences. The GPT models rely solely on the decoder and are incredible at text generation and completion.
Other models, such as the original transformer model of machine translation, have both encoder and decoder together.
The Power that Transformers have when compared to the conventional models.
Why should we discuss why transformers simply slaughtered the competition?
Speed and Parallelisation
RNNs and LSTMs operate step-by-step; in the case of a 100-word sentence, the networks require 100 consecutive steps. All 100 words are processed by transformers, and thus it trains and runs much faster.
Long-Range Dependencies
Vanishing gradient problem means that long sequences cannot be dealt with by traditional models. Transformers have perfect memory of previous sections of the sequence due to the self-attention, and they are good with long documents and complicated reasoning.
Scalability
Transformers are a good fit with additional data and computing resources. However, whereas RNNs become cumbersome on big data, transformers only improve. It is this scalability that allows us today to have models with billions or even trillions of parameters.
Applications in the Real World: Transformer Applications.
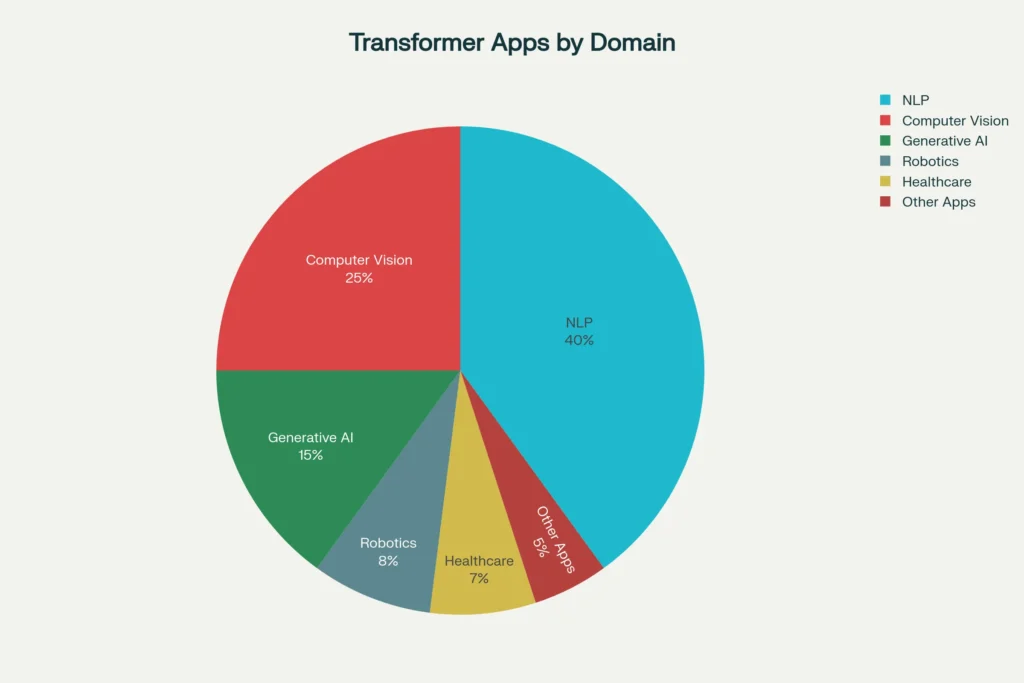
Transformer Applications Across Different Domains
Transformer Uses in Various Fields.
Transformers have much more far-reaching effects than chatbots do. These are some of the ways they are transforming various sectors:
Natural Language Processing.
GPT models drive conversational AI, content generation, and code generation.
BERT improves document understanding, sentiment analysis, and search engine.
Such machine translators as Google Translate rely on model-based translators based on the transformers to translate more accurately.
Computer Vision
Convolutional neural networks are left behind to Vision Transformers (ViTs). They consider images as series of patches and use self-attention to comprehend spatial relationships. Applications include:
Healthcare imaging and diagnostics.
Self-driving car perception.
CCTV and security programs.
Generative Artificial Intelligence and Generative Applications.
The current generative AI boom runs on transformers:
Text-to-image models such as DALL-E.
Music composition and audio Generation.
Video making and editing software.
Code Generation and Software Development Support.
Robotics and Automation
The latest literature demonstrates the adaptation of transformers to the work of robots:
Decision Transformer models can be used to make long-term plans by robots.
Natural language commands with the human-robot interaction.
Manipulation and autonomous navigation.
Difficulties and Restrictions: The Reality Check.
Transformers are not ideal even after their unbelievable success. Here are the main challenges:
Computational Demands: Transformers are consummate monsters. They have huge computational requirements in training and inference. The process of self-attention is quadratically complex with respect to sequence length, and therefore very long sequences are costly to process.
Data Requirements: These machine learning models require large volumes of training data of high quality. Millions of dollars and specialized hardware can be used to train a large language model from scratch.
Interpretability Issues: Although attention mechanisms partially give information about the way of model behavior, transformers are almost black boxes. It is difficult to understand the reasons behind them making certain decisions, and this may prove problematic in sensitive applications.
Bias and Ethical Concerns: Transformers have the potential to carry biases in the training data. This brings in critical concerns regarding justice and conscionable AI implementation.
Resource Allocation for AI Research
| Resource Category | Percentage |
| Compute | 40% |
| Data | 30% |
| Bias Mitigation | 20% |
| Research & Development | 10% |
The Future of Transformers: Future?
The revolution of the transformers is not ending any time soon. Here’s what’s on the horizon:
Efficiency Improvements
To minimise the cost of computing, researchers are coming up with better attention mechanisms. Such techniques as sparse attention and linear attention are supposed to preserve the performance and to decrease the complexity.
Multimodal Models
The text, pictures, audio, and video will be easily processed by future transformers. It is already beginning to give early manifestations of this through models such as GPT-4V or the Gemini of Google.
Specialized Applications
Transformers are also being customized to meet the scope of scientific research, legal research, and the creative industries. Every adaptation has its own challenges and opportunities.
Introduction: Slaughtering Transformers.
Wish to play with Transformers yourself? Here’s a simple roadmap:
Learning Path
Get to know the fundamentals: Begin with attention mechanisms and self-attention.
Learn the architecture: Learn about multi-head attention, encoders, and decoders.
Code Practice: Use Hugging Face Transformers or PyTorch libraries.
Play with models: Fine-tune models on tasks relevant to you.
Tools and Frameworks Popularity.
Hugging Face Transformers: Library of Transformer models.
PyTorch and TensorFlow: Deep learning frameworks.
OpenAI API: Experiments with GPT models.
Colab: Provisions of free computing The-learning-resources.
Industrial Transformers: Real Business Impact.
Transformers are being used by companies all over the world to transform their operation:
Financial Services: Transformer models are applied to fraud detection, risk assessment, and customer service automation by banks.
Healthcare: The medical facilities use transformers in case of diagnostic imaging, drug discovery, and optimization of patients.
E-commerce: Retailers use such models in personalized recommendations, inventory analysis, and customer support.
Manufacturing: Transformers are applied in manufacturing by industrial firms in predictive maintenance, quality control, and optimization of their supply chain.
The conclusion will be the Transformer Legacy.
Transformers have brought a complete evolution to the way we understand artificial intelligence. Since their modest origins as a remedy to machine translation issues, they have been transformed into the foundation of the current AI systems. It has enabled them to be indispensable due to their capacity to comprehend context, process information simultaneously, and scale with computational resources.
However, and it is here that the thing is—we are in the early years. Transformer architecture still keeps on improving, with scientists constantly discovering more efficient, more capable, and more accessible ways of making them. As a developer, researcher, or even a person interested in AI, it is important to be familiar with transformers to understand the present and upcoming future of artificial intelligence.
Whenever you next engage ChatGPT, request Google to translate something, or any other current AI system, keep in mind that you are seeing the force of transformers at work. It is not merely technology, but in fact a revolution that is transforming the way human beings and machines interact, create, and work together.
You are now prepared to explore the realm of AI? Begin to experiment with transformer models today, participate in online communities, and remain curious. AI revolution is only beginning, and transformers are in the forefront of the revolution.
FAQ’s
1. What is the difference between transformers and the old-fashioned neural networks?
Transformers also apply self-attention to the processing of full sequences at once rather than sequentially, as it was done with traditional RNNs. This parallel processing renders them quite fast and more successful in capturing long-range dependencies in data.
2. What is so strong in the transformers on the attention mechanism?
During the production of each output, the attention mechanism enables transformers to actively look at the parts of the input which mattered in the production. It establishes links among the positions in a chain at the same time, making it possible to comprehend context and relationship despite distance.
3. Is it possible to use transformers with data besides the text?
Absolutely! Transformers of images are Vision Transformers, sound processors are sound transformers, and transformers of multiple data types are multimodal transformers. The most important thing is the transformation of data into sequences which the attention mechanism is able to manipulate.
4. Why is so much processing power needed by transformers?
The computation cost of the self-attention mechanism is quadratic in sequence length, i.e., computational costs increase exponentially with length of input. Also, millions or billions of parameters are usually involved in transformers, which require considerable memory and processing resources.
5. What are the possible ways of ensuring that businesses can adopt transformers without huge resources?
The APIs (such as the GPT of OpenAI) can be used to leverage pre-trained transformer models to most businesses, or smaller models can be fine-tuned to accomplish particular tasks. Transformers are available to cloud platforms and frameworks such as Hugging Face, without the need to invest in colossal infrastructure.


Pingback: A Beginner's Guide to Prompt Engineering: How to Talk to AI? - Bing Info
Pingback: Introduction to Generative AI : The Ultimate Guide On How It Creates Text, Images, and Videos in 2025-26? - Bing Info