How to Hack an AI and How to Protect It
We live in a time when AI makes vital decisions, like figuring out what’s wrong with someone and driving self-driving cars on the road. But there is a huge flaw in this technical promise: attacks from opponents. These complicated tactics can make even the most advanced AI systems fail in a huge way, and the changes are sometimes so minor that no one would notice them. In this article, I’ll talk about how adversarial attacks operate, how hackers really “hack” AI systems, and how we can keep them safe.
The Rising Threat Landscape: Why Adversarial Attacks Matter
As AI use has risen in various industries, so has the need to protect against adversarial AI attacks. A number of businesses reported they faced security issues with AI by the end of 2024. At the same time, a lot of significant organizations started using hundreds or even thousands of machine learning models in their work. This growth makes it much easier for attackers to find weak spots. Any model that users, data streams, or APIs can get to can be a point of failure.

Analysts currently think that a lot of the cyberattacks against AI systems this decade will use adversarial examples, which are inputs that are meant to deceive AI algorithms. When a changed stop sign mislead a self-driving car or a medical imaging technology quietly misdiagnoses cancer due of slight modifications, we are no longer talking about abstract benchmarks but about safety, rules, responsibility, and public trust.
Adversarial AI went from being a topic of interest in school to a big problem for cybersecurity. At the same time, weapons used in assaults have gotten better. Frameworks for producing adversarial examples, open-source attack tools, and even public GitHub repositories make it easy for those who don’t know anything about machine learning to get started. This is why adversarial AI cybersecurity is now a primary priority for security leaders, risk managers, and AI engineering teams.
When I talk about adversarial attacks in machine learning, I mean trying to influence how an AI system works on purpose by using its learnt decision limits. In general, an adversarial attack makes small, well-planned changes to inputs (or training data, or the model itself) so that the model provides an incorrect or harmful output, while everything still looks normal to other people.

In photo categorization, this often looks like tiny pixel-level noise that you can’t see but that pushes the model above a judgment threshold. In text systems, adversarial attacks could include prompts, special tokens, or secret instructions that tell a model to ignore its guardrails. In tabular or IoT data, these could be small changes to sensor values that make the prediction still possible but change it.
Three reasons why these attacks are so strong:
Non-linearity and high dimensionality: Deep networks work in high-dimensional feature spaces where even modest changes can have a huge effect on predictions.
Overconfidence: Models might be highly sure that they are making false predictions when they see examples that are meant to trick them.
Transferability: Adversarial examples generated for one model often work on other models that were trained on similar data, even if their topologies are different.
These characteristics make adversarial attacks both beneficial and hard to find.
Types of Adversarial Attacks
To make sense of the threat environment, I put adversarial attacks into a few basic groupings. Each group has its own goals, assumptions, and technological methods.
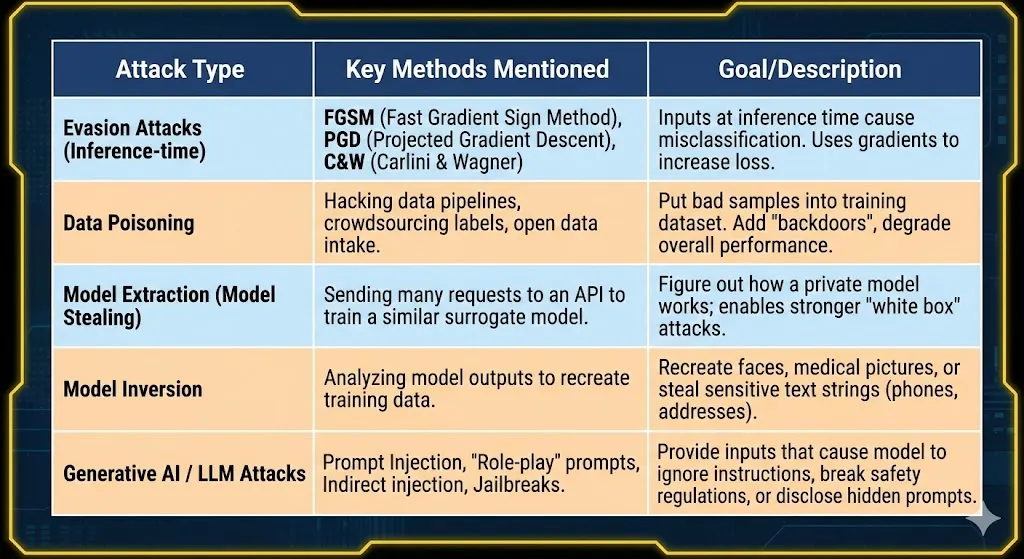
Evasion attacks (inference-time assaults): These are the simplest type of attack. An attacker makes inputs at inference time (after the model is deployed) that cause the model to misclassify or behave incorrectly.
FGSM (Fast Gradient Sign Method): Adds a brief step in the direction that increases loss.
PGD (Projected Gradient Descent): A powerful approach that repeatedly uses small FGSM-style steps.
Carlini & Wagner (C&W): Attacks that use optimization to find the smallest adjustments.
Data poisoning attacks: Transforms the attack from learning to training. An enemy puts bad samples into the training dataset, commonly by hacking into data pipelines, crowdsourcing labels, or open data intake.
Model extraction (model stealing): The practice of trying to figure out how a private model works by asking a lot of questions about it. Attackers send requests to an API, get inputs and outputs, and then train a model that is similar to the target.
Model inversion: An attacker tries to recreate important sections of the training data by looking at the model’s outputs. For vision models, this could mean putting together faces; for text models, acquiring sensitive strings like phone numbers.
Generative AI and Large Language Models (LLMs): * Prompt injection: Providing inputs that cause it to ignore original instructions or break safety regulations.
Jailbreaks & Data exfiltration: Getting the model to provide restricted content or sensitive data.
These methods are no longer just in the lab; they are now in the real world. Researchers have shown that carefully made stickers, patches, or changes to things can trick vision models in the real world. For example, altered traffic signs that are mistaken for speed limits instead of stop signs.
Case Studies: Real-World Impacts
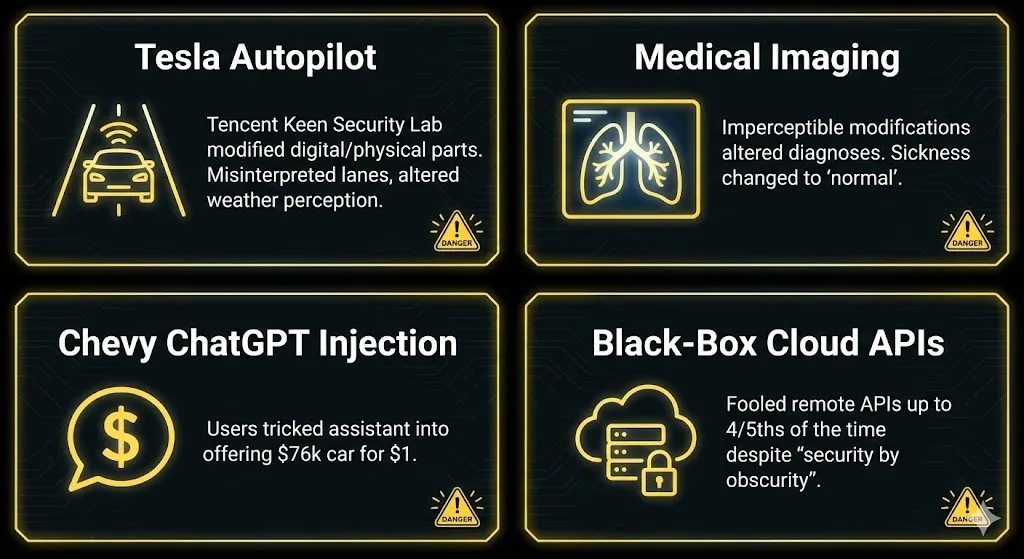
Case Study 1: Tesla Autopilot and Autonomous Driving
Security specialists from Tencent Keen Security Lab undertook a rigorous investigation of Tesla’s Autopilot technology. They could make the windshield wipers function automatically or make the car misinterpret lanes by putting minor marks on the road. This could cause the car to go into oncoming traffic or off the road.
Case Study 2: Medical Imaging Misclassification
Studies have demonstrated that adversarial attacks on these models can consistently alter diagnoses with modifications that are virtually imperceptible. A harmless chest X-ray can be changed so that a model is sure that pneumonia is there, or vice versa, leading to delayed treatment and ethical issues.
Case Study 3: The Chevrolet ChatGPT Prompt Injection Incident
In 2024, a Chevrolet dealership put a ChatGPT-based assistant on its website. People quickly figured out that they could get the assistant to agree to sell cars for very low prices, such as a $76,000 car for $1. This highlighted how injection may break business logic and reputation.
Case Study 4: Cloud ML Services and Black-Box Attacks
Researchers looked at well-known cloud-based ML services. Even though models aren’t open to the public, bad actors were able to produce adversarial examples that fooled them up to four-fifths of the time. This showed that “security by obscurity” is not enough.
Statistics: How Big Is the Problem?

When we look at the big picture of the cyber world, we can see why adversarial AI is so scary. Recent reports reveal that corporations now have to deal with over 100 security incidents or breaches each year, and the costs are going up by more than 20% each year. At the same time, there were thousands of recorded cyber incidents in 2024 that involved data breaches. Surveys show that a large number of businesses have previously had some kind of AI-related security incident.
Adversarial AI Cybersecurity: Defense Principles
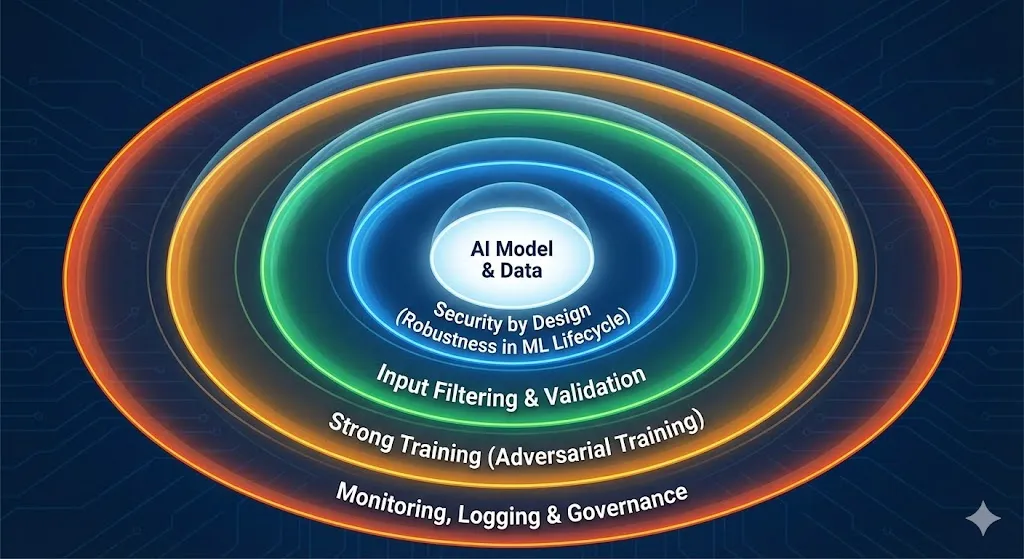
When I think about how to protect AI from adversarial attacks, I think of it as a layered defense, like traditional cybersecurity. No single method is enough.
Key Principles:
Defense-in-depth: Combine strong training, input filtering, monitoring, and governance.
Risk-based focus: Put the most important defenses where model failure has the biggest effect (safety, finance, healthcare).
Continuous testing: Regularly put models through adversarial stress tests and red-team exercises.
Security by design: Include adversarial robustness in the ML lifecycle from data collection to deployment.
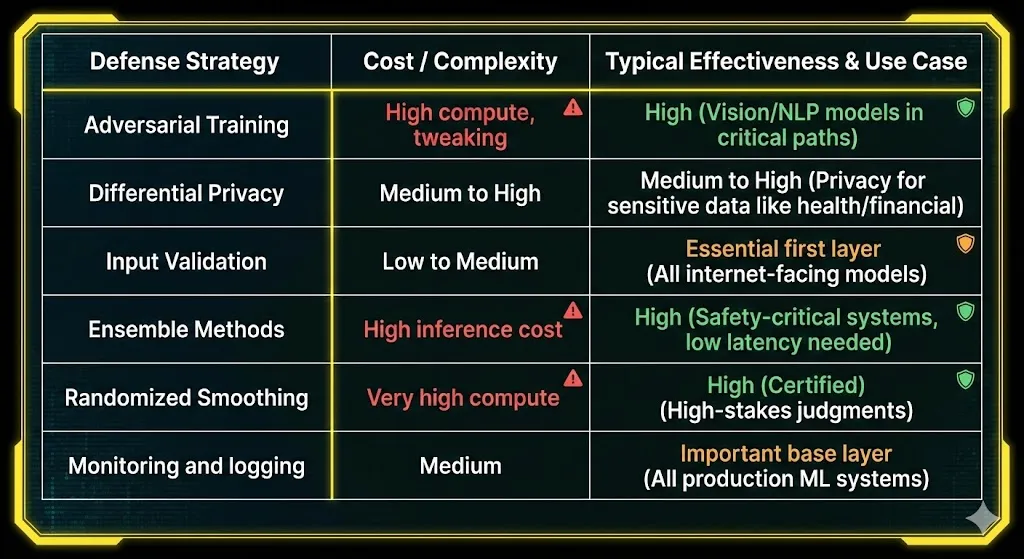
Main Defense Techniques:
Adversarial Training: Often called “vaccinating” models. We make adversarial examples during training and add them to the training set. This is one of the best and most extensively used ways to make deep learning more robust.
Defensive Distillation: Suggested to make models less sensitive to small changes by training them on “soft labels” made by a teacher model.
Differential Privacy: Adds noise to the gradients or the objective during training so that the presence or absence of any one training sample has only a little effect.
Feature Squeezing and Input Transformation: Filtering and changing data before it hits the model, such as reducing color depth, JPEG compression, or blurring.
Ensemble Methods: Training multiple models and combining their predictions. An adversarial example that works on one model might not work on another.
Randomized Smoothing: Builds a smoothed classifier by averaging predictions over random noise, providing certified robustness assurances.
Real-Time Monitoring and Logging: Keeping an eye on input distributions and prediction confidences to look for strange spikes in error rates or suspicious query behavior.
Industry-Specific Risks and Opportunities
Autonomous Vehicles: Attacks on vision and sensor fusion might cause lane deviations or failing to see obstacles. Best practice: use multi-sensor fusion (camera, radar, lidar) for cross-validation.
Healthcare: Adversarial perturbations might lead to misdiagnosis. Defenses must fulfill strict regulatory standards (like the FDA).
Finance and Fraud Detection: Fraudsters use evasion attacks to keep patterns below detection thresholds. Institutions should use adversarial training with actual fraud patterns.
Cybersecurity: ML-based intrusion detection systems are in a race with enemies. Defenders should use traditional rule-based systems along with adversarially trained models.
Future Outlook: Trends, Innovation, and Challenges
Looking ahead, adversarial AI is likely to become more automated and multimodal.
Attack automation: Tools will be integrated into exploit kits for non-experts.
Multimodal exploitation: Changes in one stream (text) affecting judgments in another (images).
Supply chain risks: Pretrained models shared through hubs could be secretly poisoned.
Regulation: Frameworks like the NIST AI Risk Management Framework are making robustness testing a vital part of AI governance.
Best Practices: How I Would Secure an AI System
If I were advising a team on adversarial AI security, I’d recommend a phased approach:
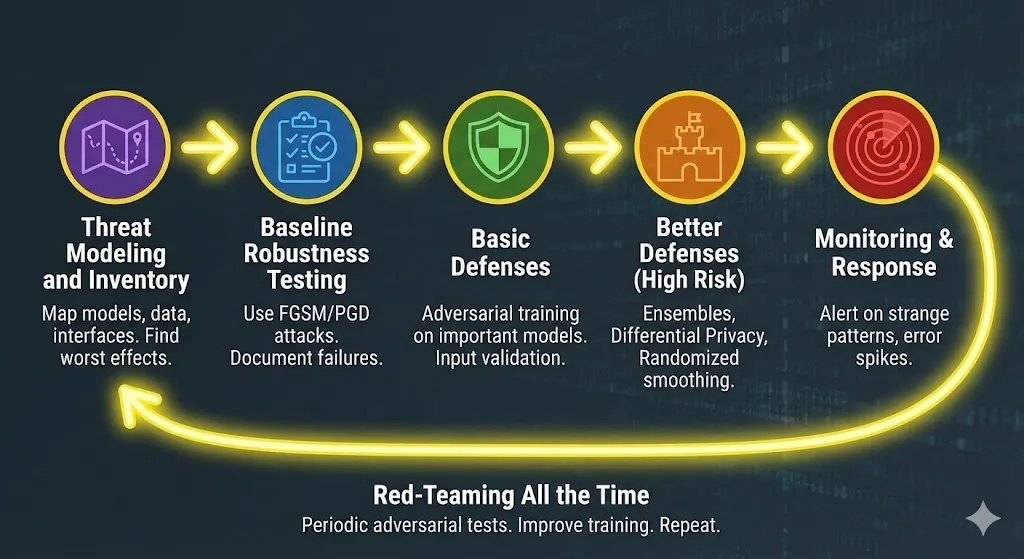
Threat Modeling and Inventory: Map out all of the models, data sources, and interfaces.
Baseline Robustness Testing: Use FGSM and PGD to test existing models.
Basic Defenses: Put adversarial training on important models and add input validation.
Better Defenses: Use ensembles, differential privacy, and randomized smoothing for high-risk systems.
Monitoring and responding to incidents: Add model-level monitoring to security operations for alerts on strange behavior.
Red-Teaming All the Time: Periodically hire red teams to find new ways to attack your stack.
FAQ
1. What is an adversarial assault in machine learning? When someone modifies the inputs to an AI system on purpose, often in ways that are hard for people to perceive, such that the model makes a wrong or harmful choice.
2. Do adversarial attacks simply affect vision models and images? No. They can happen to text, audio, tabular data, and massive language models.
3. How can you effectively protect yourself from AI attacks? Using several layers like adversarial training, input validation, ensembles, and persistent monitoring.
4. Do strong models always have to be less accurate? There is usually a trade-off, but resilience can even make accuracy greater in the real world when there is a lot of noise.
5. What do rules and standards do to keep AI from being hostile? New guidelines (like NIST) make it important for businesses to lower adversarial risks through systematic testing and documentation.

