
Introduction
The days of artificial intelligence that reads only are gone. It is an extraordinary sight–artificial intelligence capable of seeing pictures, hearing voices, and speaking like a human being with fluency. This is no longer science fiction. It is already being done with multimodal large language models (LLMs), and the consequences are astounding.
This graph indicates that the multimodal AI market is growing very fast, reaching 36.1 billion dollars by 2030, and it is estimated that multimodal solutions will make up 65% of all generative AI applications. 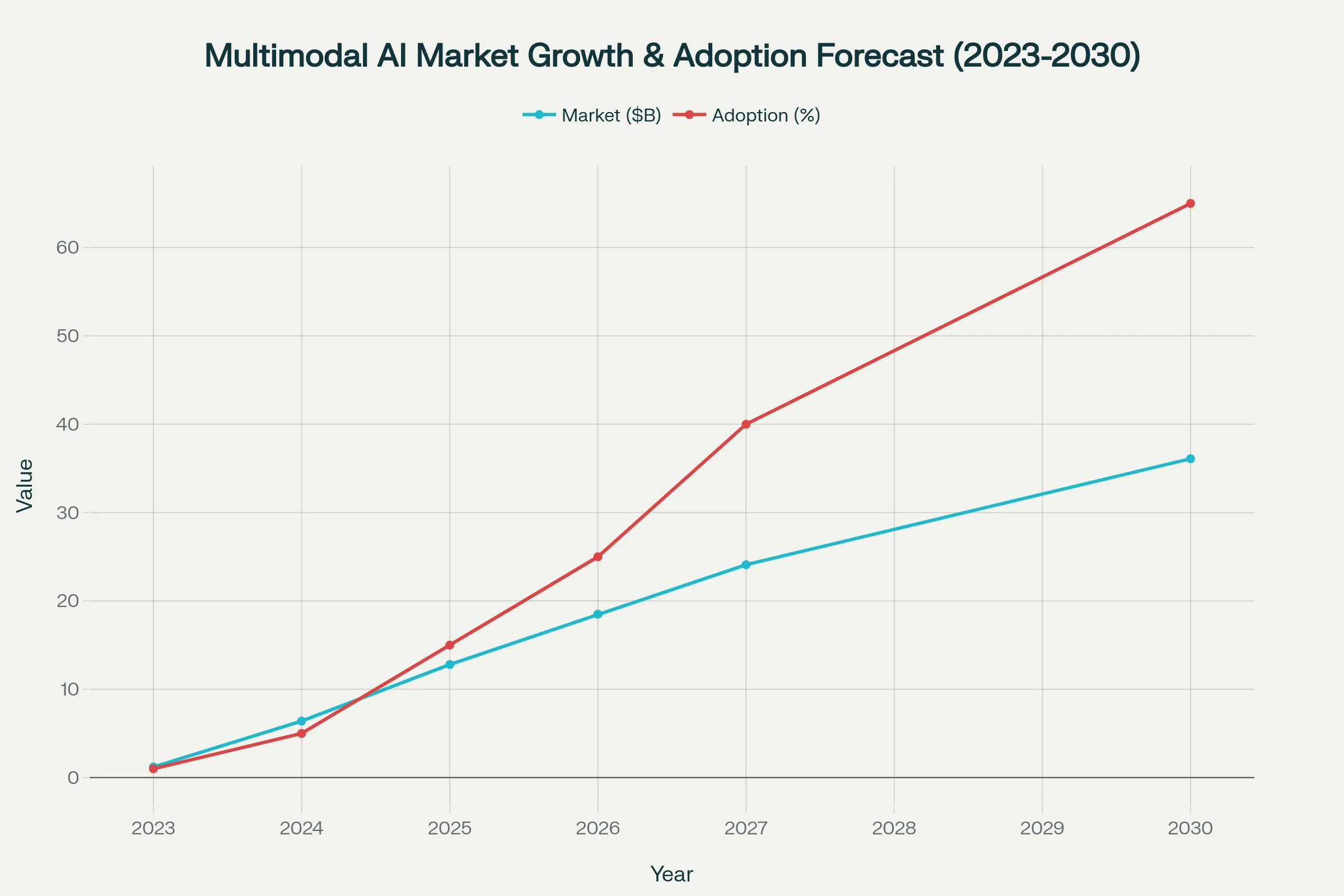
The chart illustrates the projected growth of the multimodal AI market from its current size to $36.1 billion by 2030, highlighting that multimodal solutions are expected to constitute 65% of all generative AI applications.
What Multimodal LLMs Are?
Consider your thinking process. When you are presented with a picture by someone who is telling you about something, you do not simply read what they are saying or simply observe the picture. Your brain skillfully integrates the two inputs to form an understanding. This is precisely what multimodal LLMs do, i.e. they are capable of processing multiple data types at once.
In contrast to the traditional AI models, which were restricted to one type of data, multimodal LLMs can deal with:
Text (code, natural language, documents)
Photos (pictures, diagrams, charts)
Audio (sounding, music, background sounds)
Video (moving images and sound).

Illustration showing a multimodal AI robot integrating text, image, audio, and video modalities for advanced data processing
Examples of a multimodal AI robot that combines the modalities of text, image, audio and video to process data more complexly.
The technological revolution is not only technical–it is a revolution. These systems resemble the natural human way of perception of the world as a combination of multiple streams of information.
The Real Magic: Multimodal AI In Practice.
It is at this point that it becomes interesting. Multimodal LLMs do not simply load various AI systems on top of each other. They involve complex encoding, alignment and fusion algorithms:
Encoding Phase: The processing of each type of data is handled by special encoders. Images are processed by convolutional neural networks, texts by transformer networks and audio by spectral analysis.
Alignment Phase: It is the most important stage, during which various types of data are aligned into a common representation space. It is as though we are teaching the AI the language of all the inputs.
Fusion Phase: It is the combined data produced through the attention mechanisms, or concatenation techniques, that form a single understanding.
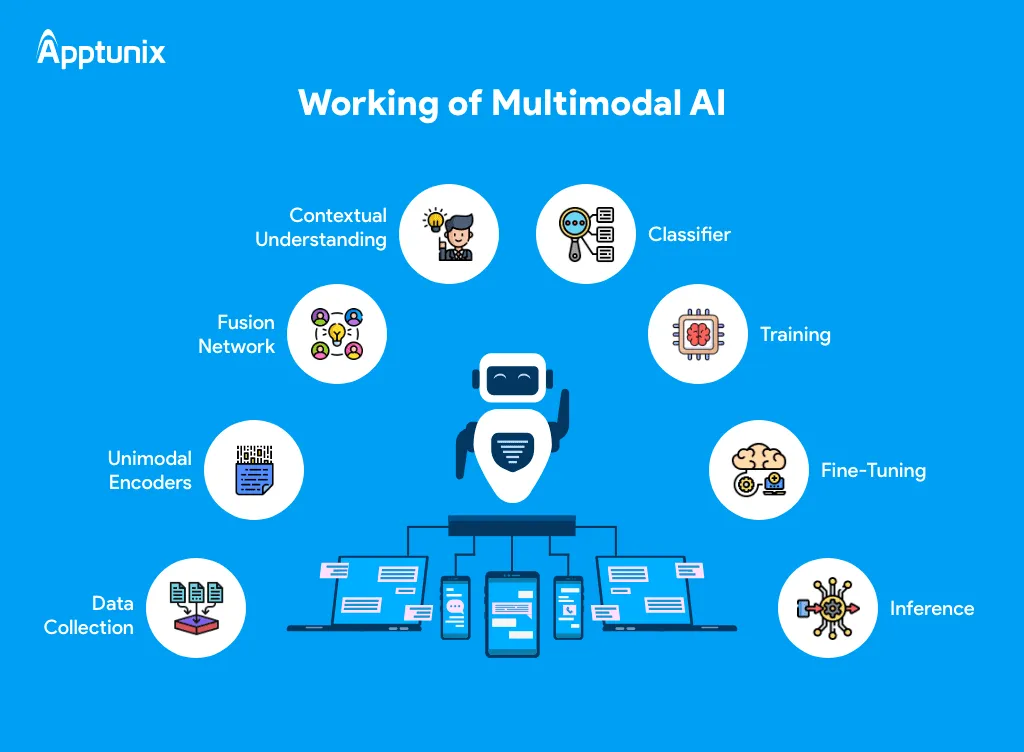 Illustration of the functional aspects of multimodal AI with steps of data collection to inference surrounding a core AI robot. Source :Apptunix
Illustration of the functional aspects of multimodal AI with steps of data collection to inference surrounding a core AI robot. Source :Apptunix
Processing Phase: The merged data is fed through the language model backbone, which allows cross-modal reasoning and generation.
ChatGPT Advanced Voice Mode: The Game-Changer.
Advanced Voice Mode of OpenAI is a ground-breaking step in our communication with AI. Advanced Voice Mode is audio-native, unlike the old system, which actually converted speech-to-text-to-speech.
The disparity is astounding:
Old Voice Mode Process:
Speech – Text transcription – GPT processing – Text to speech – Audio output.
Advanced Voice Mode Process:
Speech – Direct GPT processing – Voice output.
Visualisation of colourful waveforms and an icon of a voice assistant and speech recognition technology as a microphone. Source: Dreamstime
Users report relief from pressure when they use the new system- no more having to pronounce words carefully or make an awkward pause. The AI knows how to read the tone, emotion and context.
Current Capabilities:
Live chat with no delay.
Knowledge of emotion and tone of voice.
Natural Interruption processing.
Having several personalities.
Practical Implementations that are changing the industries.
Healthcare: Multimodal Analysis- Saving Lives.
Multimodal AI is transforming the medical diagnosis process through the integration of medical images, patient records and clinical notes. The CONCH model and its application to both pathology slides and diagnostic text can aid pathologists to be more precise in their diagnoses, such as invasive carcinoma.
Breakthrough Applications:
Pneumonia diagnosis: The integration of chest X-rays and electronic health records is more accurate than imaging.
Early cancer screening: A combination of screening imaging information and patient history will facilitate prompt intervention.
Individualised therapy: AI interprets medical records, photographs, and healthcare information to develop individual treatment programs.
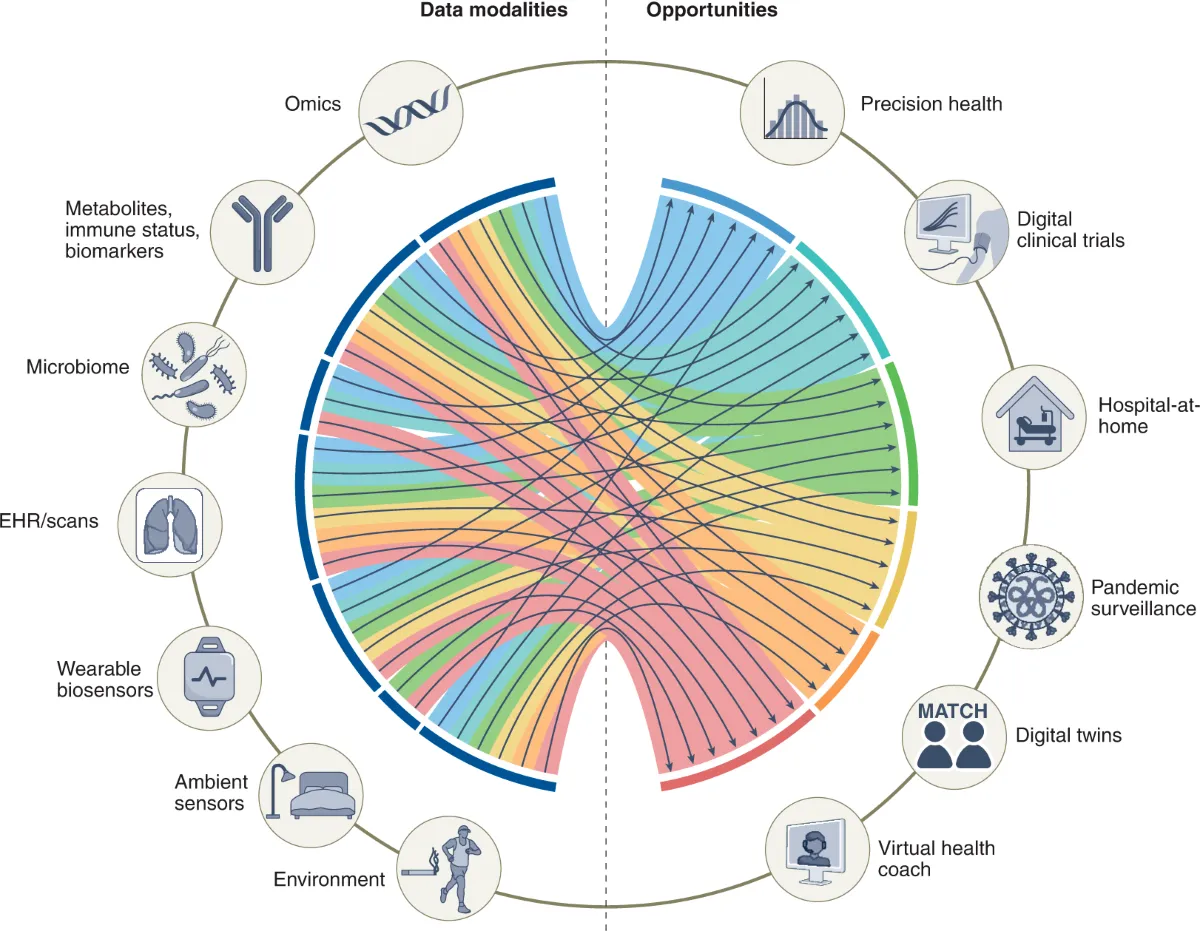
Demonstration of the multimodal biomedical data modalities associated with healthcare opportunities with a chord diagram. Source: Nature
Self-driving cars: The Future of Transport.
Cameras Multimodal AI is actually in action with self-driving cars, which process camera feeds, LiDAR information, GPS data, and sensor inputs in parallel. This combination makes it possible to make robust real-time navigation and safety decisions.
Key Capabilities:
Multiple sensors to measure the environmental awareness.
Anticipatory collision avoidance.
Optimal route in real-time.
Weather adaptation
Customer Service Revolution.
The AI aids can now respond to screenshots, voice calls and text messages at the same time and offer a broad range of support that comprehends the context of any communication channel.
Breakthrough in Voice Cloning and Text-to-Speech.
The voice cloning technology in 2025 is more sophisticated than ever before. It is now possible to clone voices in only 5-30 minutes of audio input by modern systems that support more than 140 languages and accents.
Technical Capabilities:
Zero-shot cloning: Produce convincing voices based on single short phrases.
Emotion expressiveness: Can display true emotions in speech.
Multilingual support: A Single voice speaking dozens of languages with the help of fluency.
Revolutionary Applications:
Accessibility: Reconstruction of personal voices among people who suffer from speech loss disorders.
Content scaling: Producers making hours of audio without recording.
Consistency of brand: The firms that develop signature voices in automated communication.
Voice recognition waveform visualisation of the audio amplitude versus time and output levels of AI voice recognition. Source: Predictabledesign
Multimodal Model Training: The Technical Issue.
Multimodal LLMs demand huge amounts of computation and advanced architectures to be trained. The process involves:
Architecture Design:
Transformer layer text encoders.
Convolutional neural networks are used as image encoders.
Mixed layers between modalities.
Training Requirements:
Small models (80M parameters): 4-8GB RAM
Medium models (1B parameters): 16-32GB RAM.
Big models (3B+ parameters): 64GB+ RAM.
Data Alignment Challenges:
Modality temporal synchronisation.
Processing missing or incomplete streams of data.
Semantic consistency.
Benchmarks and Leading Models: Performance.
Competition in 2025 will be impressive in terms of advancement among all large providers of AI:
Vision-Language Performance:
Google Gemini 2.5 Flash 0.75 mAP (maximum accuracy)
GPT-4.1: 0.73 mAP and good reasoning skills.
Claude 4.1: 0.71 mAP, very good face detection (83%)
Multimodal Benchmarks:
MMMU: According to its 69.1% accuracy, GPT-4o is the first.
mathvista: GPT-4o scores 63.8 per cent on mathematical reasoning.
ChartQA: GPT-4o is best at 85.7% chart understanding.
Existing Problems and Constraints.
Despite incredible advances, multimodal AI has been characterised by tremendous challenges:
Bias Amplification
Multimodal systems have the potential to combine biases of various streams of data. A resume and interview video analysing tool could be based on text-based educational biases and introduce visual appearance discrimination.
Privacy and Security Risks
The presence of several types of data allows for increased attack surfaces. Healthcare apps that work with voice messages, medical photos, and the history of patients have to secure all options at the same time.
Data Alignment Complexity
Cascading errors can be caused by misaligned cross-modal data. Without the timestamps matching the audio in video processing, the understanding of the whole system is threatened.
Computational Demands
Multi-mode processing in real time is highly computationally demanding, which is not easily accessible by smaller organisations.
The Future: What’s Coming Next
The trend is obvious–the multimodal AI will be a prevailing type of artificial intelligence:
Near-term Developments (2025-2027):
GenAI solutions will be multimodal (40% of total) by 2027 (as compared to 1% today).
Real-time APIs, which interact voice-to-voice in milliseconds.
Privacy and speed: On-device processing.
Emerging Trends:
Embodied AI: Multimodal physical environment robots.
AR/VR Integration: Immersive experiences with context-aware AI assistants.
Polyfunctional robots: Machines that can perform several tasks in the real world and communicate through human languages.
Market Growth:
By 2030, the multimodal AI market is expected to have hit $36.1 billion, and the adoption rates are expected to grow exponentially.
Real-Life Uses that you can put into Practice.
For Content Creators:
ChatGPT Advanced Voice Mode is used to create content in the style of natural conversation.
Triumph AI voice cloning of multi-lingual content.
Consider multimodal analysis of images to plan social media content.
For Businesses:
Use multimodal customer service that handles voice, text and image queries at the same time.
Hire voice agents to interact with customers hands-free.
Apply document analysis, which involves text and graphics.
For Developers:
APIs Voting APIs: Invoice APIs: Inventory APIs:
Cross-modelling Multimodal models can be used to build cross-modal applications.
test voice cloning API on accessibility applications.
In Conclusion, The Multimodal Revolution Is Here.
Multimodal LLMs are the biggest innovation in artificial intelligence since the first language models came into existence. We are no longer dealing with AI that solves one type of data; now we are dealing with systems that process all forms of human communication.
The ramifications are dramatic:
Joined data analysis will provide healthcare with more accurate diagnoses.
It will be a safe way to transport people with the fullest knowledge of the environment.
Advanced voice interactions will help in making communication more natural.
There will be enhanced accessibility with the help of customised AI.
It is not merely technological advancement, but the advent of AI, which thinks more like human beings think, processing the multimodal world that we actually inhabit.
Want to get acquainted with multimodal AI? Begin with the Advanced Voice Mode of ChatGPT, learn multimodal image analysis, or read the technical documentation of the most popular models. The future of AI interaction is here and now and it is more to be accessed than ever.
FAQ’s
1. What is the difference between multimodal AI and regular AI?
Multimodal AI is able to process more than one type of data (text, images, audio, video) at the same time but traditional AI can handle only one type of data. This allows deeper insight and less artificial communication.
2. Is ChatGPT capable of interpreting my tone of voice and my feelings?
ChatGPT has an Advanced Voice Mode, which is audio-native and understands the tone of voice, as well as emotion and context without first converting audio to text. This brings about more natural, human-based conversations.
3. What is the amount of data required to clone the voice of a person?
Current AI voice cloning systems can convincingly generate voice imitations using only 5-30 minutes of high-quality audio, and some systems also accept much shorter audio samples.
4. What are the primary privacy issues of multimodal AI?
Multimodal AI systems are advanced systems that handle various types of sensitive data at the same time and they pose multifaceted privacy concerns. Even the harmless individual data streams may unintentionally disclose personal information by means of a cross-modal analysis.
5. When is the multimodal AI going to become mainstream?
The concept of multimodal AI is already gaining traction and it is estimated that 40 percent of generative AI applications will be multimodal by 2027. The technology itself is now in consumer use such as ChatGPT Advanced Voice Mode and a range of business applications.

