
Privacy-Preserving Machine Learning: A Comprehensive Guide to Federated Learning and Beyond
Privacy is important, especially when machine learning models are based on private information. I’ve seen firsthand how hard it is for companies to find a balance between protecting data and coming up with new ideas. This tension has only grown stronger as rules like GDPR and HIPAA require stricter protections. I want to talk about one of the most revolutionary ideas in modern AI today: Privacy-Preserving Machine Learning (PPML). Specifically, I want to focus on federated learning and the set of techniques that keep data safe while still allowing for powerful collaborative intelligence.
The Privacy Crisis in Machine Learning
The traditional way of doing machine learning has a big problem: we need to put all of the sensitive data in one place to train good models. Hospitals combine patient records, banks combine customer transactions, and tech companies collect behavioral data—all in centralized data lakes where hackers, bad insiders, or regulatory violations can put millions of people’s private information at risk.
Key Statistic: This weakness became impossible to avoid between 2024 and 2025. Data breaches cost businesses an average of $4.45 million each time they happen. Under the GDPR, fines can be as high as 20 million euros or 4% of global revenue, whichever is higher.

But here’s the most important thing to remember: we don’t need to centralize data to train good models. We need to put learning at the center, not information.
In 2017, Google researchers came up with the idea of Federated Learning (FL) after they realized this. Since then, the market for privacy-preserving machine learning has grown a lot.
Global Federated Learning Market Growth Forecast (2024–2030)
Below is a projection of the market’s rapid expansion:
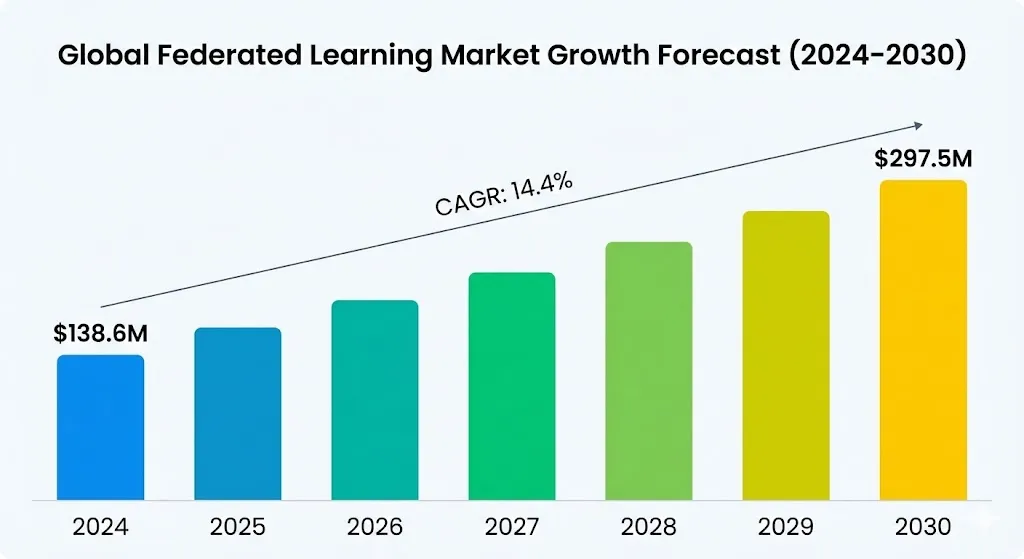
Global Value (2024): $138.6 million
Expected Value (2030): $297.5 million
Compound Annual Growth Rate (CAGR): 14.4%
US Market (2030): Expected to be worth $68.6 million (15.9% annual growth rate).
Comprehending the Fundamental Privacy-Preserving Methods
When we talk about machine learning that protects privacy, we’re really talking about a set of tools that work well together. Each one solves a different part of the problem, and the best solutions often use more than one method.
1. Federated Learning: Keeping Data Close to Home
Federated Learning is what makes decentralized AI work. FL trains models directly on devices or institutional servers where data lives instead of sending raw data to a central server.
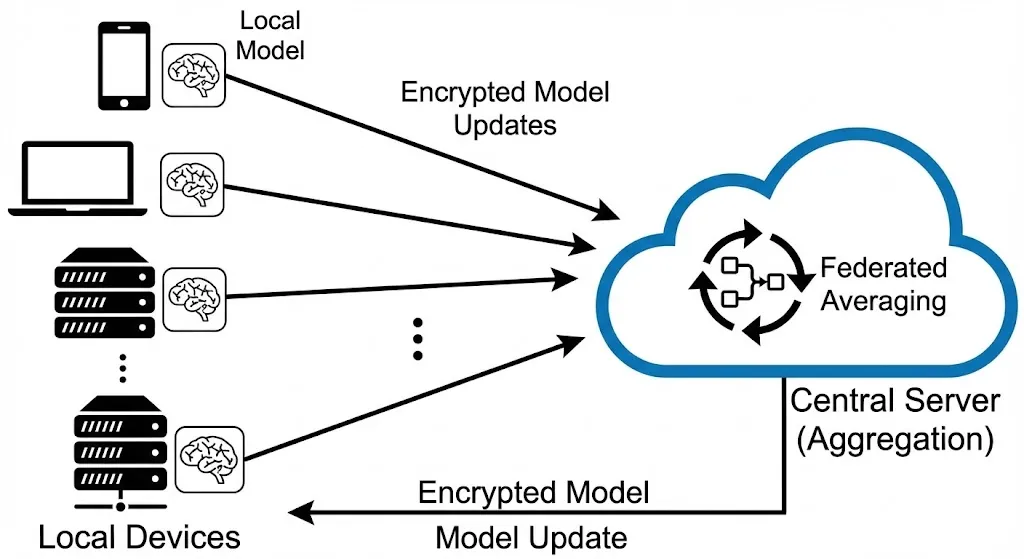
How it works:
Training in the Area: Each person trains a model copy using only their own data, which stays on their device or in their organization.
Sharing Model Updates: Only the updated model parameters (weights and gradients) are sent to a central server. The raw data is not sent.
Aggregation: The server uses algorithms like Federated Averaging (FedAvg) to combine these updates. FedAvg calculates the weighted average of all client updates.
Global Model Distribution: The enhanced global model is dispatched to all participants for the subsequent training round.
The beauty of this method is how easy it is: everyone can use their collective intelligence without giving away private information. This is perfectly shown by Google’s use of Gboard (Google’s keyboard). The system trained an LSTM-based language model on 1.5 million clients who processed 600 million sentences together.
A comparison of machine learning methods that protect privacy
2. Adding Protective Noise to Differential Privacy
Federated Learning keeps raw data on the user’s device, but gradient inversion attacks can leak sensitive information through the model updates themselves. This is where Differential Privacy (DP) is very important. DP adds noise to gradients in a very precise way, making it impossible to figure out what individual training data points were.
The technical basis is the idea of -differential privacy, which limits the chance of information leaking:
Small : Privacy is better, but the model may not be as accurate.
Large : The model learns better, but privacy guarantees get weaker.
3. Homomorphic Encryption: Working with Encrypted Data
Homomorphic Encryption (HE) lets you do calculations on encrypted data without having to decrypt it first.
Encryption Before Transmission: Each client uses their public key to encrypt their model updates.
Direct Aggregation: The server combines the encrypted values.
Results Stay Encrypted: The aggregated result stays encrypted until clients use their private keys to decrypt it.
4. Secure Multi-Party Computation: Working Together to Compute Without Being Seen
Secure Multi-Party Computation (SMPC) lets more than one party work together to compute a function using their own private inputs and only show the final result. A 2025 study found modern implementations can cut down computation by 1.25% compared to older methods.
Real-World Uses: How Privacy-Preserving ML Makes a Difference
Case Study 1: Mobile Keyboards and Google Gboard
More than 1 billion people use Google Gboard. The federated solution used a version of LSTM called Coupled Input and Forget Gate (CIFG).
Efficiency: Cut model parameters by 25%.
Size: Final model was only 1.4 megabytes.
Case Study 2: Siri’s ability to recognize voices on Apple devices
Apple uses local model training and Differential Privacy noise to gradients to stop reconstruction attacks. Users still have full control over their voice data while AI gets more and more personalized.
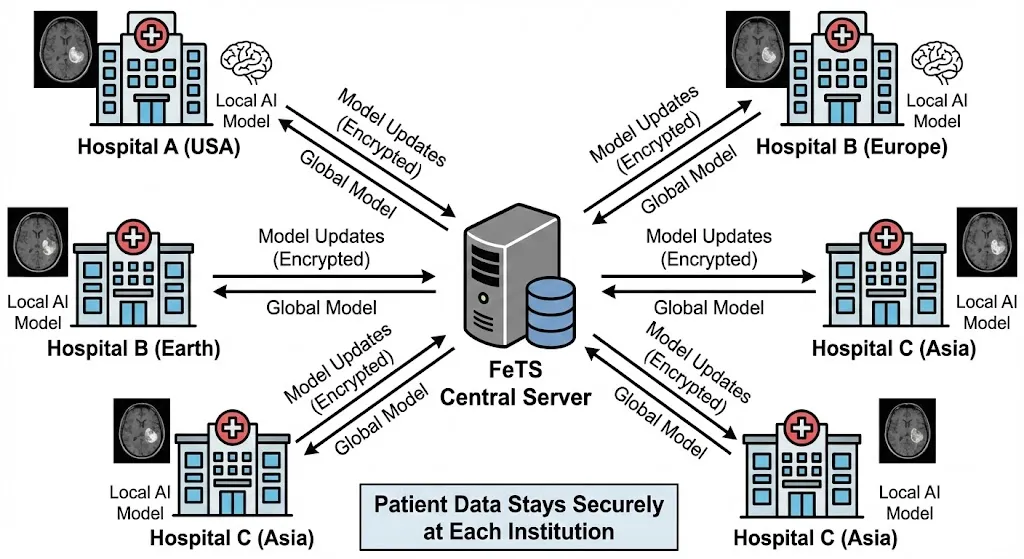
Case Study 3: Healthcare—How to Share Data Without Violating Privacy
Patient data is protected by HIPAA. FeTS (Federated Tumor Segmentation) brought together 30 medical institutions globally to identify brain tumors.
ML that protects privacy and follows the law
Federated learning is in line with the main ideas behind GDPR, which are data minimization and privacy by design. A formal report in June 2025 stated that FL works perfectly with GDPR when done correctly.
How FL Meets Regulatory Requirements
The Attack Surface: Knowing About Privacy Risks
1. Attacks that invert gradients
A 2025 study showed that FET (Fully Expose Text) accomplished:
39% better exact match rates for TinyBERT-6.
20% better for BERT-base.
2. Attacks on Membership Inference
These find out if a certain person’s data was used by looking for patterns in model confidence using a “shadow model.”
3. Data Poisoning and Model Reversal
Data poisoning happens when bad actors put bad data into local sets to lower global model quality.
Secure Federated Learning: Best Practices
Use More Than One Method: Defense in Depth (FL + DP + HE).
Use secure aggregation protocols: Such as GVSA to stop the server from seeing individual updates.
Carefully Add Differential Privacy: Use values between 0.5 and 2.
Monitor for Memory: Use canary strings to find overfitting.
Do an Adversarial Evaluation: Test against gradient inversion regularly.
Keep records: Full transparency for forensic analysis.
Difficulties and Choices
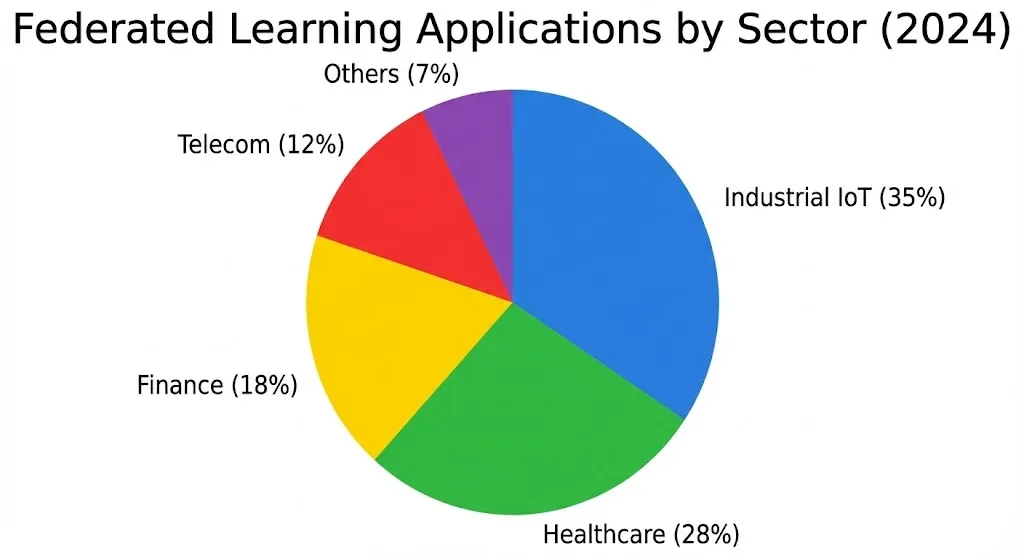
Federated Learning Applications by Sector (2024)
The Future of Machine Learning that Keeps Your Privacy Safe (2025–2027)
Mixed Architectures: Combining federated and centralized learning.
Improvements in Cryptography: Post-quantum homomorphic encryption.
Federated Learning That Is Personalized: Training models specific to institutions (e.g., Columbia’s radiation therapy work).
Adding blockchain: For aggregation and verification.
Changes in rules: Clearer guidelines following the EDPS 2025 report.
Questions People Ask a Lot (FAQ)
Q1: Is federated learning really private? A: It lowers risk a lot by keeping data local. However, it requires Differential Privacy () to be truly secure against advanced attacks.
Q2: Why use FL if it makes models less accurate? A: Accuracy loss is usually small (<2%). It is a trade-off for GDPR compliance and user trust.
Q3: What industries get the most out of FL? A: Industrial IoT (35%), Healthcare (28%), and Finance (18%) are the leaders.
Q4: What does differential privacy really do? A: It adds calibrated noise to gradients (e.g., turning into ) to stop individual data reconstruction.
Q5: How does FL differ from regular data anonymization? A: Anonymized data can often be re-identified (73% of the time in healthcare). FL never shares the data in the first place.
Conclusion: Making the Future Safe for Privacy
We are at a very important point in the growth of AI. Federated learning changes privacy from an afterthought to a basic design principle. The future of machine learning is not centralized, is private by design, and is focused on people. And it’s already here.


Just did the jili17login. Fast and simple. No headaches. Now ready to have some fun! Website definitely seems set up nice. You can log in here: jili17login.