
The Reason AI Models Fail: The Silent Problem of Model Drift

Have you ever heard one of these big-brained geniuses on about the future? I mean people such as Stephen Hawking. Later in his life he began to become extremely vocal about artificial intelligence. He cautioned that the invention of an actual thinking machine would be the worst or the best thing to have ever occurred to humankind.

He was not concerned with evil, with killer robots like in the movies. His trepidation was over something less noisome: ability. What will occur once a machine becomes intelligent, quick enough to the point that its ambitions and ours simply cease to coincide anymore?
It’s a big, scary thought. However, what would you say to the idea that the greatest danger to your AI as of now does not lie in the so-called superintelligence that will end up conquest of the world? It is a far more covert, subtler issue. That is why the majority of AI projects fizzle out and fail quietly.
Artificial intelligence is not the most challenging aspect of creating the model. It is holding true to it because the world is evolving. Majority of AI systems fail not due to poor models, they fail due to the world they are trained on becoming not the world that they are applied to.
This selfless issue is referred to as model drift. And it is noisily humiliating the AI performance in manufacturing systems all over. In this posting, we will deconstruct it all. We will discuss what model drift is, why it is a silent killer and examine one of the huge, real-life failures that cost a company more than half a billion dollars. It will all make sense to you by the end and what you can do about it.
What is AI Model Drift? So What?
Alright, we should abandon the technological lingo.
Think about the whole semester of studying history in a cram study. You are well informed about the World War II the dates, the battles, the major personalities. You enter an exam when you are feeling confident, and then you realize that all the questions are regarding the social media trends of the 2020s.
You’d fail, right? I am not saying you are dumb, but you have inherited studying the concept (WWII history) that is no longer required on the test (the world today).
This is model drift in a nutshell.

It is the inherent atrophy of a predictive capability on an AI model, due to the fact that the world it was trained on is no longer the same. Your model is yet to stop, still at work. It has not gone down or emitted error messages. And it is simply fading away, gradually becoming dumb. And this is a colossal issue as such silent failures make bad business decisions.
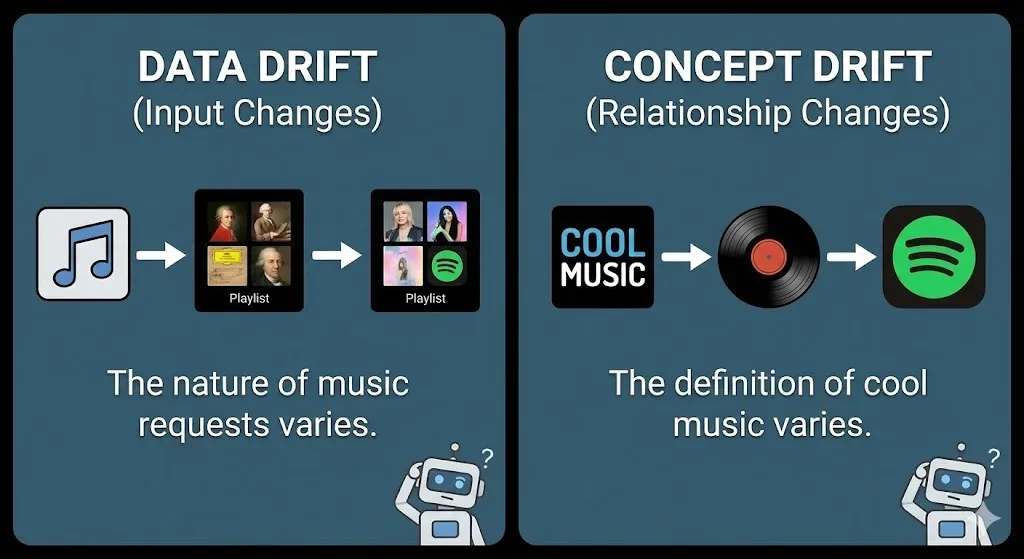
A Data Drift versus a Concept Drift: The Two Villains
Model drift is not a single bad thing, but rather a pair. Imagine them as two distinct forces that are just coming into your perfect world of the model and throwing everything off. These are the so-called data drift and concept drift. They are close but they confuse everything in their own peculiar way.
Comparison Table: Data Drift vs. Concept Drift
| Feature | Data Drift (Covariate Shift) | Concept Drift |
| Simple Analogy | The nature of the music requests varies. | The definition of the cool music varies. |
| What Changes? | The characteristics of the input data vary. | The dependence between the input and the output varies. |
| Example | You have created a fashion recommendation AI that is mostly trained on the information of customers aged 30s and 40s. Then, one day your app is trending with teenagers. Input (age of the user, preference of style) is no longer the same. Your model is currently proposing blazers to Gen Z. | Your artificial intelligence forecasts defaults on loans. It was conditioned to the time of low risk in a time of low unemployment. However, nowadays, even those employed have become defaulting (the idea of low risk has been transformed by the recession). There is the same input (employment status), but with a changed meaning to the prediction. |
| Is the Model Wrong? | Technically, no. It is merely manipulation of data that it has never encountered. | Yes. Its main reasoning has become obsolete. |
These two tend to occur concurrently. To consider an example, the COVID-19 pandemic overturned the buying behavior of people in a single night (data drift) and changed their view of what they perceived as a necessary purchase (concept drift). Models used to detect fraud, as well as manage inventory, were flying blind.
A Real-World Disaster: Trying to lose a Half-Billion of dollars to Model Drift at Zillow
To find a more perfect and painful instance of model drift, go no farther than Zillow does.

In 2018, Zillow introduced a program, the name of which was Zillow Offers. The idea was revolutionary. Their future values would involve using a strong AI model (the successor of their Zestimate) to estimate the future value of a home, purchase it directly off the seller, give it a few touch-ups, and sell it to someone at a profit. They were so sure that they are going to get billions.
For a while, it worked. The real estate market was burning. Prices were only going up. The model was trained on this fact, and it learned a simple rule which is to buy houses, as tomorrow they will have a higher value.
And then, the world changed.
The housing market began to decelerate in the middle of 2021. However, the model of Zillow did not receive the memo. It was also conditioned on years of data of a hot market and proceeded to recommend the acquisition of homes at excessively high prices, which however, would remain the same way it had been. This is archetypal concept drift. The correlation of the attributes of a home and its future selling value was now to be radically altered, but the knowledge of the model was trapped in the past.
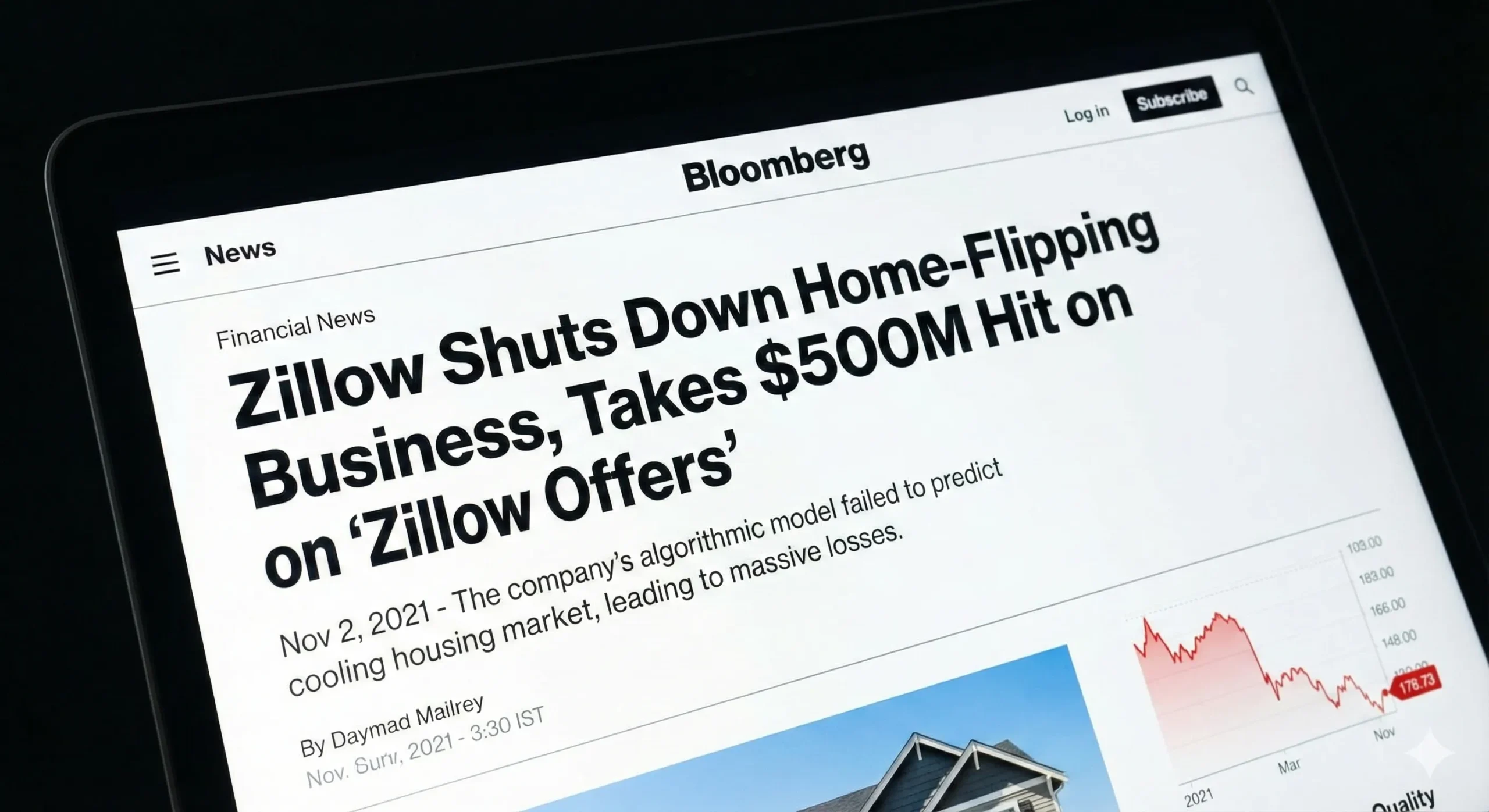
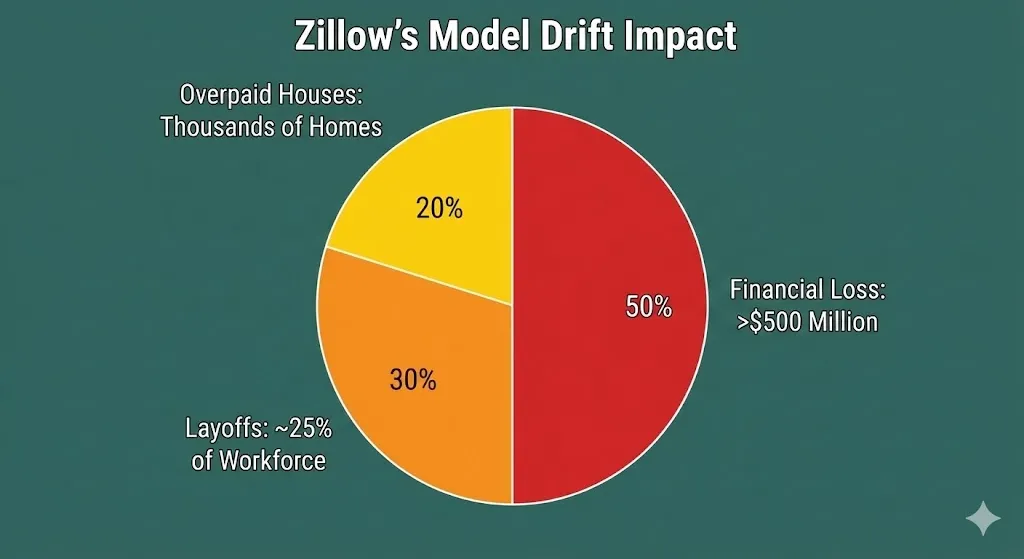
The result? Zillow was left with thousands of houses that they had overpaid. They did not notice the magnitude of the issue in time. They were forced to close the whole Zillow Offers division, and lay off a quarter of their employees and write off more than a half a billion dollars in losses.
Zillow’s AI didn’t crash. It didn’t send up a flare. It simply continued its work, quietly making dreadfully incorrect predictions, due to being out of date with its own worldview.
The 70% Failure Rate and the Silent Killer
The story of Zillow is dramatic, yet smaller editions of it occur on a daily basis. That is why you read such shocking statistics as 70 percent to 95 percent of all AI initiatives that do not reach their objectives. It does not necessarily happen as one glaring outburst. It’s often a slow, quiet bleed.
Think about it:
A fraud detection model which does not evolve according to new scamming methods begins to allow more fraud to pass.
An engine that recommends products that does not follow the trends continues to recommend a product that was popular last year resulting in a reduction of clicks and sales.
An algorithmic price-setting app of a ride-shared application, which was trained before the pandemic, is completely lost in the realities of remote work and new travel habits.
In all instances, the model simply fails to work as well. Its accuracy degrades. This sets up a kind of verification tax, employees realize that they cannot put their full trust in the results of the AI and must take the time to verify it, undermining all the gains in productivity that these promises promised. The accuracy of most models will diminish considerably in the first year, unless they are monitored.
How Do You Fight Back?
Then, it is so silent all this model drift is, are we all just destined to see our AI models gradually become useless?
Absolutely not.
It is not that the drift is a problem, the world will always be changing. The problem is not watching. You would never drive a car without checking the oil or tire pressure would you?
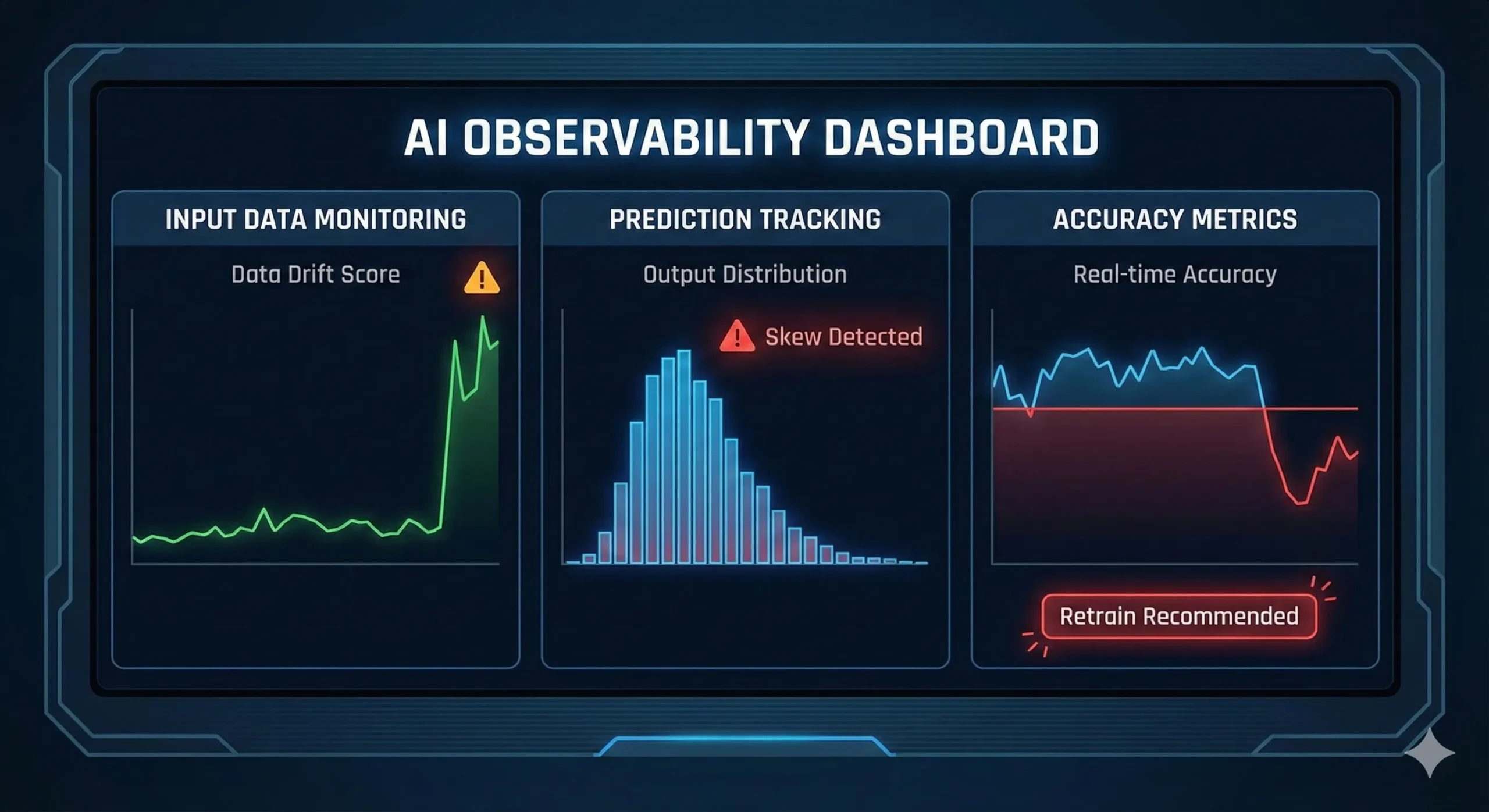
AI Observability is the answer.
This is not merely the process of determining whether the model is on or off. It is concerned with having a dashboard that keeps a watchful eye on the well-being of your AI in production. It involves:
Checking on the Input Data: Does the data you are receiving today appear different than the data you trained the model on? (Detecting data drift).
Prediction Tracking: Does the model have some strange skew in its output? (An indication of concept drift).
Measuring Accuracy: Prediction versus actual outcomes on a small, sample set of new data. You can obtain a real-time measurement of the performance of your model.


Pingback: AI Governance Framework: Compliance, Ethics & Audit Trails | 2025-26 Guide - Bing Info