
Introduction- Why Training AI Models Like LLMs Is So Expensive
The process of training large language models (LLMs) has rapidly become one of the most costly undertakings in contemporary technology, reaching truly astounding figures that make even the most daring technological projects seem comparatively small. The economic truth is stark: while the initial Transformer architecture cost only $930 to train in 2017, state-of-the-art designs, such as Google’s Gemini Ultra, now cost over $191 million to train. It’s estimated that training costs will reach up to $1 billion by 2027.

Modern AI data centre showcasing high-density GPU clusters
Such an astronomical cost isn’t just a set of numbers on a spreadsheet; it’s transforming the entire landscape of AI, influencing which organisations can compete in the race to artificial general intelligence and how we even think about technological innovation as a whole. Understanding these expenses isn’t merely an academic pursuit; it’s essential for anyone involved in AI, investing in the field, or attempting to comprehend why artificial intelligence development remains largely in the hands of a few hyper-rich tech corporations.
The Exponential Cost Explosion: From Thousands to Hundreds of Millions
The increase in AI training costs has been breathtaking. Research conducted by Epoch AI shows that the cost of training frontier models has grown 2.4 times per year since 2016. This implies that training the most advanced models becomes significantly more expensive each year.
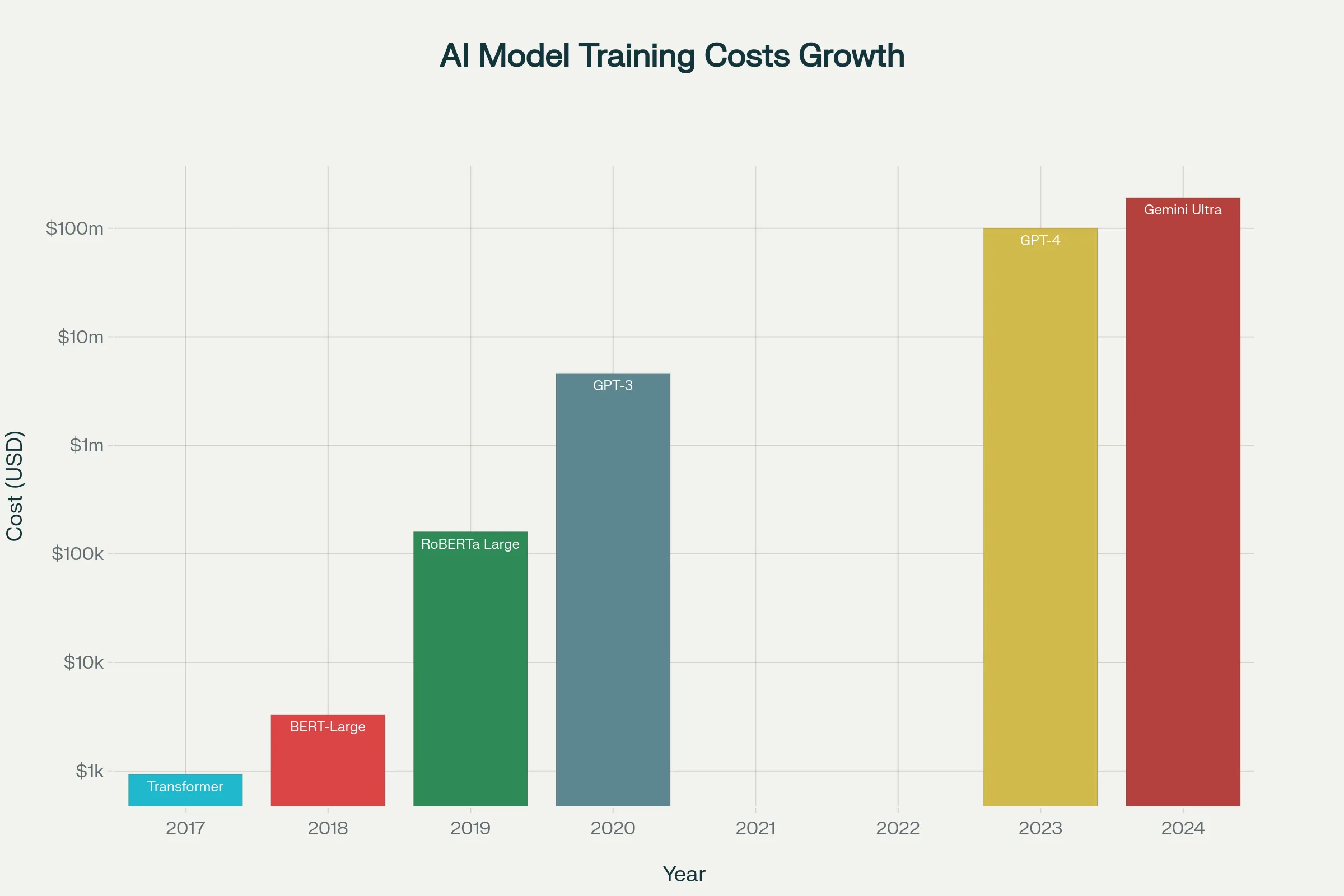
The exponential rise in AI model training costs from 2017 to 2024
In perspective, this cost increase has been far more dramatic than Moore’s Law projections. In 2020, OpenAI’s GPT-3 cost approximately $4.6 million to train. Within just three years, the training costs for GPT-4 exceeded $100 million. This represents over a 20-fold increase in three years—a growth rate that would seem slow by the standards of the most costly infrastructure development initiatives.
The Stanford Artificial Intelligence Index Report indicates an increase of 4,300 per cent after 2020, resulting in a 44 times higher price within a four-year timeframe. This rapid trend shows no signs of decelerating, with analysts estimating that the biggest training programs could surpass $1 billion by 2027.
Hardware: The AI Training Money Pit
Specialised computing hardware is the main contributor to these astronomical expenditures. Modern LLM training requires thousands of large Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs) operating continuously for several weeks or months. These are not your stereotypical consumer graphics cards; rather, they are enterprise-grade processors specifically designed for machine learning workloads.
NVIDIA’s H100 AI training GPUs range in price between $25,000 and $40,000 each. The mathematical implications are truly incredible: it takes thousands of such GPUs to train a model like GPT-4. A single cloud instance with eight high-performance NVIDIA A100 GPUs is priced at over $23,000 per month to rent, and training can take several months.
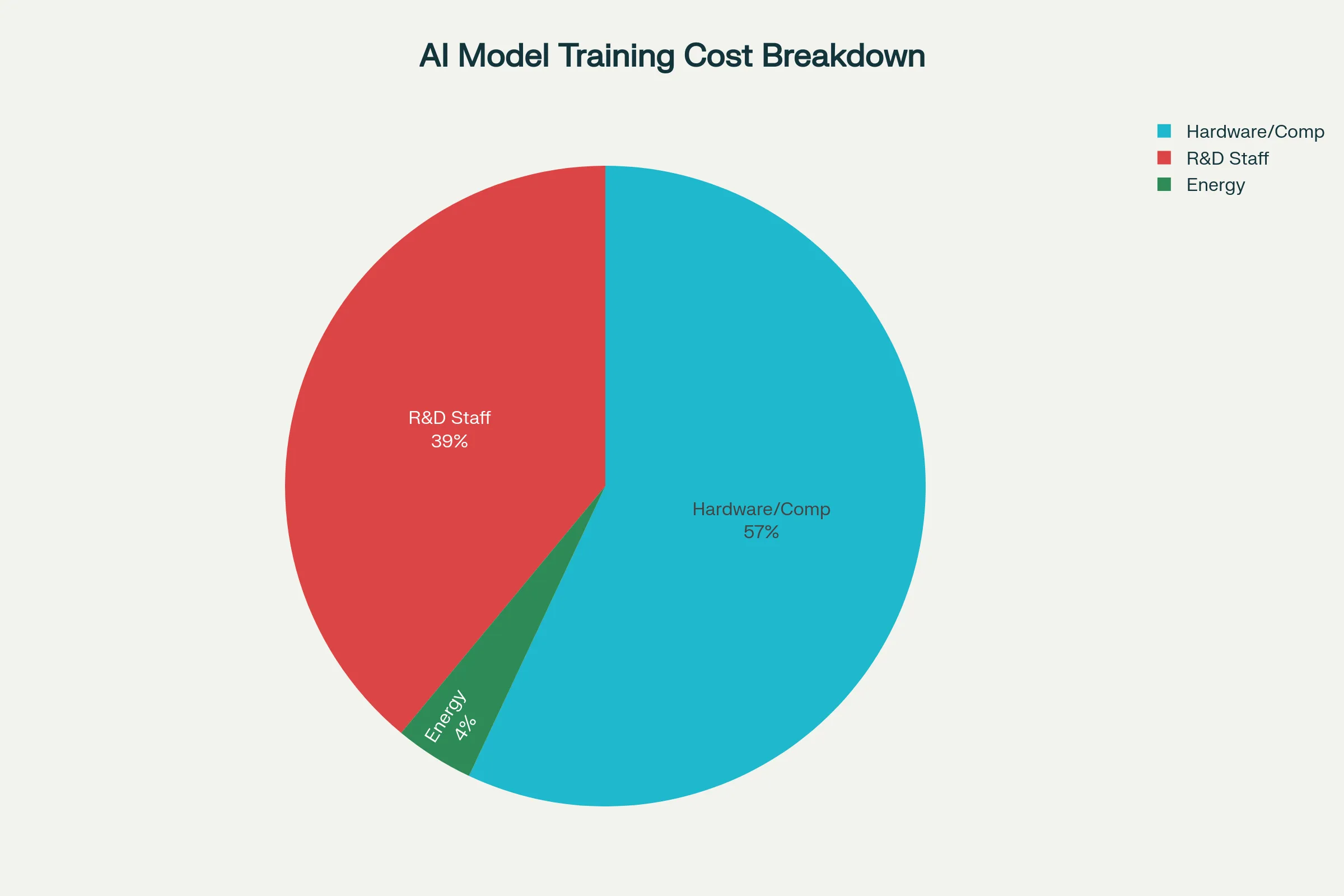
Cost breakdown for training frontier AI models like GPT-4
Training Frontier AI Models such as GPT-4 Cost Breakdown
The hardware expenses do not end with the processors. Based on Epoch AI’s cost breakdown, hardware costs are expected to constitute 47-67 percent of the overall training costs. This includes:
AI Accelerator Chips: The GPUs or TPUs that perform the actual calculations are the most expensive single category of expenses.
Server Components: Powerful CPUs, huge memory (usually terabytes), and very high-speed storage systems to support the processors.
Networking Infrastructure: Special interconnects that enable thousands of processors to communicate with one another without significant latency, which accounts for 9-13% of the total costs.
Cooling Systems: Commercial-quality cooling systems to manage the massive heat produced by tightly packed processors.
This complex hardware ecosystem implies that organisations cannot simply purchase a few expensive computers. They require constructing or renting full data centres specifically configured to process AI workloads, generating power densities of up to 120 kilowatts per server rack—as opposed to standard data centres with a typical power density of 12 kilowatts per rack.
The Human Capital Crisis: When Machines Are Cheaper Than Talent
Human talent is the second-most expensive area in the development of AI models, constituting 29-49 per cent of the total costs, even though hardware often grabs headlines. The AI arms race has resulted in a compensation arms race that would make even professional athletes envious.
The Million-Dollar Engineer
Leading AI scientists and technologists can now command salaries formerly unheard of. In some businesses, such as Meta, senior research engineers have a maximum base salary of $440,000, and Google offers software engineers a top base salary of $340,000. However, these amounts are not the complete story—add to them stock grants, signing bonuses, and profit-sharing agreements, and overall compensation packages can easily reach millions of dollars annually.
Senior research engineers at OpenAI typically have a base salary between $200,000 and $370,000, but their total packages, including equity, can amount to $800,000 to $1 million. The highest-paid AI researchers are reportedly being offered compensation packages of up to $250 million over several years, bordering on the level of NBA superstars.
The Geographic Premium
Location is incredibly important in AI talent expenditures. Machine learning engineers and principal engineers now earn six-figure salaries starting at £150,000 and going as high as £300,000 in senior roles in London. In Silicon Valley, the premiums are even greater, with specialised jobs in computer vision, natural language processing, and large-scale systems engineering costing 25-45 per cent more than more traditional software engineering jobs.
The Reason the Talent Shortage Is Here to Stay
It’s not merely whether companies have large pockets; it’s about basic scarcity. There are extremely few people with the expert skills to design, train, and optimize frontier AI models. Such professionals must have profound knowledge of:
Mathematics and statistics
Data Structures and Algorithms (DSA)
Optimization algorithms
Large-scale data processing
Parallel computing and GPU programming
Artificial neural network designs
These skills are combined in a way that makes them rather rare, and companies therefore pay very high additional premiums to acquire the best talent. According to one industry executive, until companies are forced to spend billions of dollars manufacturing models, they will continue to spend tens of millions or even hundreds of millions to hire engineers to work on their projects.
Energy: The Raw, Unspoken Environmental and Financial Cost
Although the percentage of expenditure on energy use is lower than that on other expenses (usually 2-6 per cent), the amounts involved are huge, and the impact on the environment is immense. Training GPT-3 required about 1,287 megawatt-hours (MWh) of electricity, or approximately the annual electricity consumption of 120 American households.
The Power Consumption Reality
The actual training processes of AI today require massive power systems. Google’s Gemini Ultra training needed 35 megawatts of power, which is sufficient electricity to supply a small city. To put this in context, a simple historical extrapolation of power consumption over time suggests that AI supercomputers might demand gigawatt-scale power by 2029.
An NVIDIA A100 consumes about 400 watts at peak power consumption. Multiply that by thousands of GPUs running for months at a time, and the electric bills are enormous. The amount of electricity required to train a large model on 1,000 A100 GPUs might be as high as 400 kilowatts per hour, which would imply enormous electricity bills even in areas where electricity is inexpensive.
Infrastructure and Cooling Costs
The power bills are not limited to powering the processors. Current AI data centres demand advanced cooling options to handle the massive heat produced by tightly packed GPUs. Up to 40 per cent of all data centre power might be spent on cooling, and AI data centres produce much more heat than conventional computing stations.
Liquid cooling is also being migrated to some facilities to enhance efficiency, though these are also expensive in terms of additional infrastructure. All this complicates energy as a major sustaining operational cost during the training process because of the combination of direct power consumption and cooling needs.
Information: The Fuel That Runs the AI Engine
Another key element of cost, commonly disregarded in high-level cost discussions, is training data. Contemporary LLMs are trained on enormous datasets consisting of trillions of tokens (single words or even fragments of words) from which the model learns.
Acquisition and Licensing of Data
High-quality training data is not easily acquired. Companies must either:
License existing data: This can cost millions of dollars to obtain comprehensive, high-quality text corpora from sources such as news organizations, academic publishers, and content creators.
Develop own datasets: This involves a high cost of human labor in terms of data gathering, preparation, and data quality assurance.
Web scraping and processing: Even free web data requires enormous processing to gather, clean, and format into training datasets.
Costs of data acquisition and processing, according to industry cost breakdowns, are usually 5-10% of overall training costs, which can run into tens of millions of dollars for frontier models.
Data Preprocessing and Data Storage
Raw data is not immediately trainable. The preprocessing pipeline consists of:
Culling of duplicated material.
Filtering to eliminate low-value text.
Standardisation of format and tokenisation.
Content moderation according to safety and legal requirements.
This preprocessing is computationally intensive and also requires expert knowledge. The resulting processed datasets then have to be stored in high-performance storage systems capable of supplying data to thousands of GPUs at a time, further increasing the cost of additional infrastructure.
The Scaling Laws: Why Bigger Is Always More Expensive
The basic cause of the ongoing explosion of AI training expenses is the mathematical principle known as scaling laws. These empirical findings demonstrate that model performance, when scaled up, is predictably linked to a combination of three major factors: model size (number of parameters), dataset size, and compute resources.
The Mathematics of Scaling
Scaling laws are often power laws, with performance improvement logarithmically proportional to increases in resources. The most simple form can be written as:
L(N) = (N₀/N)ᵃ
Where L(N) is the loss (error rate) with N parameters, N₀ is a constant unique to a model, and a is the scaling exponent. This mathematical model demonstrates that to experience any substantial performance enhancement, you must have exponential growth in resources.
The Trillion-Parameter Future
The parameters of current frontier models are in the hundreds of billions. GPT-3 contains 175 billion parameters, with recent models approaching or surpassing the trillion-parameter threshold. These parameters require memory to maintain and computing power to update during training. It is not a linear relationship—it takes a lot more than twice the computational resources to simply double the number of parameters because the training algorithms are complex.
Why Smaller Models Are Not Good Enough
The scaling laws explain why companies cannot afford to simply train smaller, low-cost models. In most cases, there exist threshold effects where, below a certain size, models are simply incapable of performing the needed work expertly. This presents a stark decision: either spend the colossal amounts necessary for frontier-scale training or be forced to tolerate much lower quality capabilities.
Infrastructure: Construction of AI Factories
The infrastructure necessary to train frontier AI models gives more of an appearance of industrial manufacturing facilities than conventional data centers. The scale and complexity of these “AI factories” constitute a huge chunk of the cost architecture.
Data Centre Transformation
Conventional data centres are developed to support a general computing workload with a power density of 12 kilowatts per rack. The power densities in AI training facilities may exceed 120 kilowatts per rack and are expected to rise in the future to 200-250 kilowatts per rack. This basic difference demands totally different methods towards:
Electrical Infrastructure: AI data centres require industrial-quality electrical infrastructure that can support enormous power loads with minimal downtime. The power distribution systems should be designed with significantly higher capacities compared to those in traditional facilities.
Cooling Systems: Thousands of high-performance processors produce heat that needs industrial cooling systems. Liquid cooling systems are being migrated to in many facilities and require special plumbing and coolant distribution departments, as well as advanced leak detection systems.
Network Architecture: High-bandwidth, low-latency networking is crucial to coordinate thousands of processors when training large models. Networking infrastructure in itself can take up 9-13 per cent of the overall training expenses.
Geographic Considerations
Infrastructural demands are shifting AI training centres away from traditional tech hubs towards areas that have abundant access to inexpensive power. This reflects the historical development of the aluminium industry, which moved from urban centres to regions with large power-generating capacity due to its high energy needs.
Businesses are also investing in plants close to renewable energy sources or areas that have good electricity rates. Others are even developing their own power generation capacity to ensure a reliable, cost-effective power supply for their AI operations.
Economics of Fine-Tuning vs. Training From Scratch
Not all AI applications necessarily need models to be created from scratch. Fine-tuning, which involves taking an existing pre-trained model and adapting it for specific tasks, is a less expensive approach for many applications.
Fine-Tuning Cost Advantages
Fine-tuning a pre-trained model generally costs between $100 and $1,000, as opposed to the millions of dollars it costs to train a model from scratch. Such a drastic price difference enables the use of AI in a wide range of organisations that could not afford to develop frontier models on their own.
It is based on the idea of harnessing the already acquired general information in large models and dedicating computational resources to task-based adaptations. The model does not require learning language understanding from zero but just needs to learn the particular patterns required in the target application.
When Fine-Tuning Isn’t Enough
Nevertheless, fine-tuning has limitations. In scenarios where the application needs something that is not available in current models, or where an organisation wants full control over its AI systems, training from scratch is still required, even with the large costs.
Fine-tuned models also reflect the biases and drawbacks of the underlying models. Strict model behaviour requirements or operating in situations too different from the training data used to train the base model can result in inadequate fine-tuning.
The Vendor Lock-In Trap
The high expense of AI model training poses significant risks in terms of vendor dependency and pricing power. The cost incurred by organisations that use external AI services is a constant expenditure that can rise without notice.
API Pricing Dynamics
Companies such as OpenAI, Anthropic, and others sell API access to their models at a price per token. Although single API requests are fairly cost-effective, the price can easily climb when applications have high usage volumes. There are vast differences in token pricing between providers and model levels, which makes it very complicated to optimise costs.
The Multi-Vendor Strategy
To prevent the risks of vendor lock-in, a significant number of organisations are employing multi-vendor strategies and maintaining compatibility with a variety of AI vendors. But this strategy requires extra overhead for development and maintenance, as various models might need different prompt engineering methods and may also have different capabilities.
Selection between Building and Buying
These excessive prices of training frontier models imply that most organisations will have to decide between:
Making continuous API payments to access state-of-the-art models.
Investing in models with finer details that best meet their needs.
Creating bespoke models (generally not cost-effective for small-budget organisations).
The cost structures and risk profiles of each method differ, and long-term economics should be carefully analysed.
Gazing into the Future: The Billion-Dollar Barrier
The trend of AI training prices does not indicate a moderating trend. According to current projections, the largest training runs will reach over $1 billion by 2027, establishing a new reality where only the most well-endowed organisations can afford to build frontier AI capabilities.
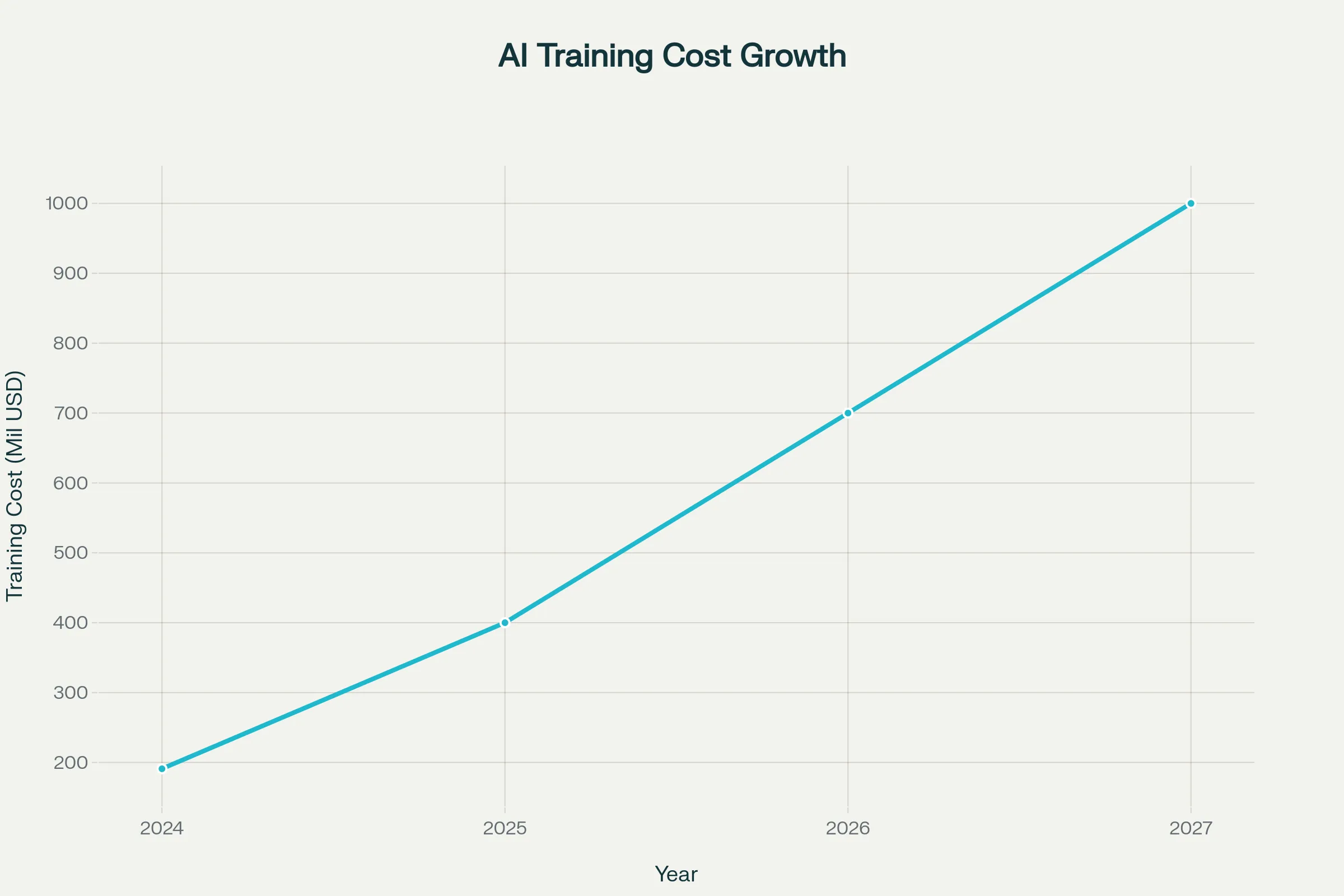
Projected AI model training costs reaching $1 billion by 2027
Market Concentration
Such huge expenditures will tend to increase concentration in the AI development market. The development of a frontier model will be accessible only to tech giants such as Google, Microsoft, Meta, and OpenAI, as well as well-financed startups and government agencies. Such a level of concentration raises significant concerns related to rivalry, innovation, and the availability of sophisticated AI-based solutions.
Efficiency Improvements
However, the industry is also making heavy investments in efficiency gains that may moderate cost growth:
Hardware Optimisation: Next-generation AI chips are being made more efficient, offering higher performance at a lower price per dollar and per watt.
Algorithm Improvements: Researchers are developing improved training algorithms that can achieve the same results with minimal computational resources.
Specialist Architectures: Specialist model architectures designed for specific tasks can use less computational power than general-purpose models.
Alternative Approaches: Methods such as retrieval-augmented generation and mixture-of-experts models are potentially options that can be used to obtain high performance at reduced training cost.
The Strategic Implications
The huge expenses involved in AI training are transforming competitive forces in the technology industry and beyond. Companies need to develop advanced methods of tapping into AI functions without depleting their finances or endangering their future.
For Enterprises
The majority of enterprises will need to focus on fine-tuning and application-layer innovation rather than foundation model development. The economics strongly suggest that it is much better to use existing models and modify them for particular use cases instead of training them from scratch.
For Startups
The cost barrier presents both opportunities and challenges for startups. While only a few can afford frontier model training, there are big opportunities in specialised models, efficiency enhancement, and application development using existing models.
For Society
The monopoly of AI development potential by well-financed actors has significant policy implications regarding competition, accessibility, and the social effect of AI technologies. Policymakers are also grappling with the issue of how to ensure widespread access to AI benefits and how to deal with the challenge of concentrated technological power.
The Future of AI Training Economics
Several trends will probably define the economics of AI training in the future:
Further Cost Increases: In the absence of significant technical advances, the cost of training frontier models is expected to keep increasing exponentially, potentially reaching multi-billion-dollar amounts in the next decade.
Efficiency Innovations: A great deal of research is focused on how to cut the costs of training with improved algorithms, hardware designs, and training methods.
Democratization Efforts: Open-source projects and cloud-based training tools can be used to make AI development more accessible to smaller organisations.
Regulatory Responses: Governments might have to respond to the competitive implications of concentrated AI development capabilities.
One of the biggest obstacles to ubiquitous AI innovation is the economic reality of the cost of training AI. As technologies keep evolving at a very high rate, the financial demands impose core limitations on who is able to be involved in frontier AI development. These costs and their implications are important to learn and understand by any person working in or with artificial intelligence technologies.
To implement AI strategies, organisations should pay significant attention to the economic considerations of various solutions, balancing performance needs with cost issues. Financial viability will define the future of AI development (just as much as technological potential will), and cost optimisation will form a vital part of successful AI projects.
It is not simply cost inflation that has seen the transition of the $930 Transformer to billion-dollar training runs, but this is actually the paradigm shift of AI from a field of study to an industry-scale technology creation project, with the whole world economy at stake.
FAQ’s
1. Why not just use smaller and cheaper models instead of spending hundreds of millions?
Scaling laws in AI demonstrate that as models grow in size, they become predictably more accurate. There are often threshold effects where models below a particular size are simply incapable of performing their intended tasks at a useful level. While smaller models require only hundreds or thousands of dollars to fine-tune, compared to millions of dollars to train a model of the same capacity ex nihilo, frontier capabilities often demand a frontier-level investment.
2. What are the comparisons of the cost of AI training and other significant technology investments?
AI model training has become one of the costliest technology development ventures. GPT-4, estimated at over $100 million to train, surpasses the development budget of most software products and matches the budgets of Hollywood blockbusters. The ambitious projected cost of training of $1 billion by 2027 would make frontier AI development one of the most capital-intensive technology projects ever.
3. Will the training expenses keep on increasing exponentially, or are changes in efficiency going to decrease them?
Trends have indicated an increase in training costs by 2.4 times per year since 2016, although various forces may impact this. Costs may be reduced by hardware enhancements, increasing the efficiency of algorithms, and novel model architectures such as mixture-of-experts systems. Nevertheless, the basic scaling laws imply that it will still require considerable amounts of resources to achieve significant performance improvements.
4. What percentage of AI training costs goes to electricity and energy use?
The cost of energy consumption generally accounts for 2-6% of overall training expenditure. While this may not appear to be a large amount, it translates to millions of dollars for frontier models. GPT-3 required 1,287 MWh of power to train, equivalent to the annual power consumption of 120 households. As models become larger and training becomes longer, the environmental cost and the cost of electricity are likely to increase dramatically.
5. Are there ways that organisations can use AI without millions of dollars to train the model?
Absolutely. It is less expensive to fine-tune existing models than it is to fully train models, making efficient AI features accessible to smaller organisations. While API access to frontier models has ongoing costs, it avoids the huge initial investments in training. Most successful AI applications are based on using and adapting existing models for specific applications rather than training them from scratch.

