Explainable AI (XAI): Making Models That Are Hard to Understand Easy
AI makes some of the most important decisions that affect our lives without us even knowing it. AI is used by banks to decide whether or not to give out loans. AI helps hospitals figure out what diseases people have. Self-driving cars can make decisions on our roads in a flash. But the scary truth is that we don’t know why a lot of these systems did what they did. One of the biggest problems with AI right now is the black-box problem.
I want to take you on a trip through the world of Explainable Artificial Intelligence (XAI), which is changing how we build, use, and trust AI systems. We’ll talk about why models are hard to understand, why it’s important for them to be open, and most importantly, how we can turn these strange black boxes into systems that people can trust and check.
The Black-Box Problem: When Unclear Information Affects the Real World
To understand how important XAI is, we need to know why complicated machine learning models turn into black boxes in the first place. When we train deep neural networks, gradient-boosted tree ensembles, or other complex architectures, they learn to find very small patterns in data—patterns that are so complex that it’s hard for people to explain them clearly.
Think about a deep neural network that is made to sort medical pictures. There are dozens of layers in the network, and each layer could have millions of settings. Each parameter makes the final prediction a little bit better, but the way the parameters work together makes it very hard to make a decision. The model can find tumors with 98% accuracy, which is better than what radiologists can do in controlled studies. When we ask the doctor who uses this system, “Why did the AI flag this patient’s scan?” they often say, “I don’t know—the model didn’t tell us.”
This lack of openness is a big problem for AI right now. More complicated models are better at finding nonlinear relationships and small interactions between features that simpler models can’t. But this very complexity makes it very hard to understand why they did what they did.
Image :Diagram comparing a traditional Black Box AI model versus an Explainable AI model.
In the real world, the effects are very bad. Researchers who looked into COMPAS, an AI system used in criminal justice to figure out who is likely to commit crimes again, found that the algorithm was unfair to Black defendants. There were a lot more false positives for black defendants than for white defendants. The judges couldn’t figure out if the bias came from the model’s structure, the training data, or hidden interactions between features because the system was hard to see through. These differences would have been clear right away if XAI techniques had been used.
Healthcare professionals are reluctant to follow AI suggestions when the reasoning behind them is not clear. Radiologists may not trust an AI’s tumor diagnosis if they can’t see which pixels were used to make it. This is the opposite of what the AI was supposed to do.
Regulatory bodies now require businesses in finance to explain automated decisions that affect customers. Banks must tell people who apply for loans why they didn’t get them. AI systems that don’t explain how they work don’t meet these requirements, which makes them legally responsible.
What does it mean to have “explainable AI”?
It’s the link between things that are hard to understand and things that are easy to understand.
Explainable Artificial Intelligence (XAI) is the field of study that tries to make the choices that AI systems make clear, understandable, and interpretable to people who care about them. But XAI is more than just putting explanations next to predictions. There are many parts to the plan, and they all work toward three goals that are all related:
Interpretability is how easy it is for people to see how a machine learning model changes inputs into outputs. It’s easy to understand a linear regression model that guesses how much a house will cost. Each coefficient shows you how much the predicted price goes up or down when you add one more unit of a feature, like the number of bathrooms or the square footage. When a deep neural network makes the same prediction, we can’t see how each neuron changes the final output.
Transparency, we mean how easy it is to see how data moves through a system and how inputs become outputs. In a decision tree, we can see all the rules and branches. It can be hard to understand how a neural network with millions of parameters made its choices.
Trustworthiness, you need to do more than just understand. It also means having faith that a system works, follows moral rules, and makes choices that are fair. Even if a system is honest about being racist, that doesn’t mean you can trust it. But for trust to really grow, there needs to be openness so that everyone can see that systems are doing the right thing.
We differentiate between two fundamental methodologies for attaining explainability. Intrinsic interpretability means that models are made so that people can understand them without having to explain them later. Linear regression, decision trees, and rule-based systems are all simple models that are easy to understand. Their structure shows how decisions are made. Post-hoc interpretability refers to the application of explanatory techniques on pre-trained black-box models to elucidate their decision-making processes subsequent to training completion. Two examples of this method are LIME and SHAP. They let us break down models that would be hard to understand if we didn’t have them.
XAI: Making AI Clearer by Comparing Black-Box AI and Explainable AI
The Fast Growth of XAI: How Businesses Are Using It and What the Market Is Doing
There has never been a rise in the use and investment of XAI like this. In 2024, the global XAI market was worth about $7.94 billion. It should grow by 18 to 20 percent every year and be worth $26.9 billion by 2030. Some studies say that growth will be even faster, with estimates going up to $37.4 billion by 2033.
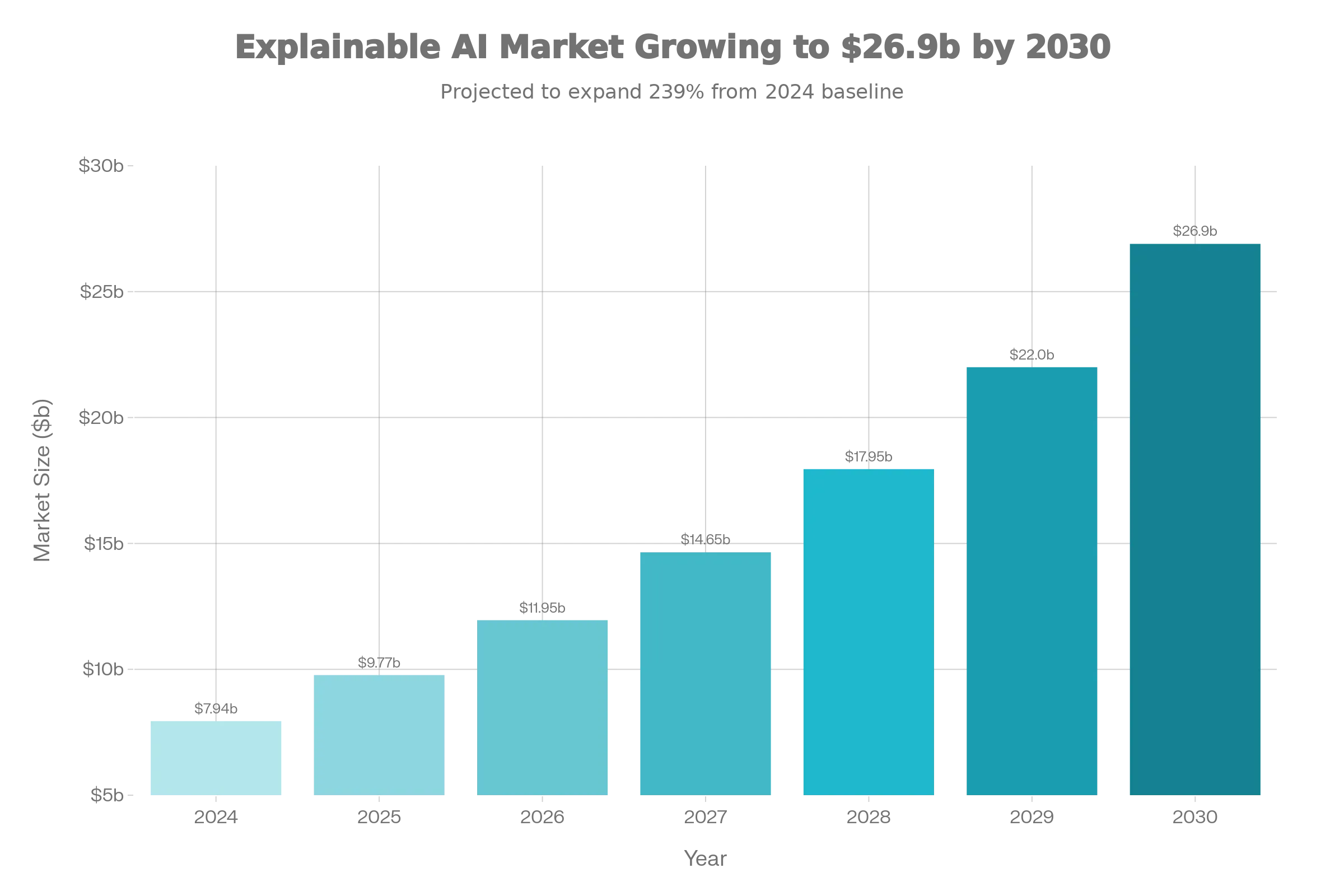 Graph: Chart showing the projected growth of the Global XAI Market Size from 2024 to 2033.
Graph: Chart showing the projected growth of the Global XAI Market Size from 2024 to 2033.
This big growth is the result of many things coming together. First, you can’t ignore rules and laws anymore. The General Data Protection Regulation (GDPR) of the European Union says that decisions made by computers must be clear and open. The new EU AI Act says that some systems are “high-risk” and that they must be able to be explained at every stage of their life. The U.S. Federal Trade Commission (FTC) is keeping a close eye on AI systems to make sure they are fair and don’t favor one group over another. This review is mostly based on how easy it is to understand.
Second, a lot of demand in the industry is a clear sign of competition. Businesses know that AI systems that are simple to use and work well with customers make people trust them and lower the risk of being sued. Banks and other financial institutions have been able to cut down on false positives by up to 30% by using XAI to find fraud. This helps compliance teams focus on real risks. When healthcare systems use XAI, doctors are more confident and more likely to follow AI advice.
In 2025, 83% of businesses say that AI is one of their most important goals. Businesses need to deal with the issue of transparency in a planned way because so many people use it. In apps that directly affect people or in fields that are regulated, it’s not okay to use models that aren’t clear.
Intrinsic Interpretability: Making things clear from the start
The best way to make models that are easy to understand is to build them that way. These clear architectures aren’t as good at predicting things as they could be, but in many fields, this trade-off is worth it.
Linear and Logistic Regression: Feature Weights That Are Easy to Understand
Linear regression is likely the simplest machine learning technique to comprehend. The model learns one weight (coefficient) for each input feature. Then it uses these weighted values to make guesses. A linear regression model that predicts house prices might learn that the final price is $150,000 plus $200 for every square foot, minus $5,000 for every year the house is old, and plus $75,000 for every bathroom.
This is very simple. Even people who aren’t technical experts can quickly figure out how the model works if they are working on the project. The price goes up with more square footage, homes that are older are worth less, and homes with more bathrooms are worth more. It’s easy to understand how the model works because it uses simple math to explain how it makes choices.
Logistic regression takes things a step further by letting you do classification tasks (making yes/no predictions) while still being easy to understand. A logistic regression model that predicts whether a loan will be approved might show that applicants with credit scores above 700 and debt-to-income ratios below 0.43 are very likely to be approved, while those with scores below these levels are very likely to be denied.
It’s also clear that the limitation is that relationships in the real world aren’t always linear. The price of a house doesn’t go up in a straight line with the square footage. Larger homes may not have as much value. To understand how features work together, we need nonlinear models. For example, neighborhoods that cost a lot may become more valuable more quickly than neighborhoods that cost less.
Decision Trees: Rules that Help You Make Choices
Decision trees use feature values to split data into smaller pieces, which creates a structure of if-then rules. This is how a decision tree that shows you how likely you are to get credit might work:
If the credit score is lower than 650, you can be sure that it is a high risk.
When the debt-to-income ratio is higher than 0.5, there is a medium risk.
There is a medium risk if there have been more than three recent inquiries.
Expect a low risk otherwise.
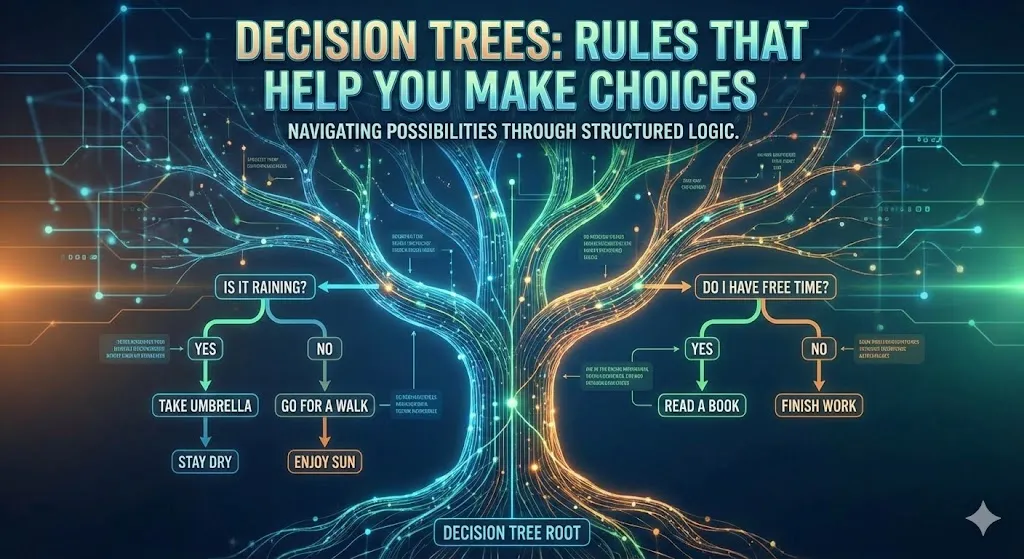 Image : Decision Tree diagram illustrating credit risk assessment based on credit score and debt-to-income ratio.
Image : Decision Tree diagram illustrating credit risk assessment based on credit score and debt-to-income ratio.
Anyone who is involved can see how decisions are made in any case. People who care about the issue can check that the reasoning is in line with domain knowledge and standards of fairness because of this openness. A compliance officer can quickly see which features affect decisions and if there are any bad relationships, like zip codes that are linked to loan denials.
But it can be hard to understand deep decision trees with a lot of branches. A tree with hundreds of nodes is too hard for people to remember. Also, decision trees can overfit, which means they remember noise in the training data instead of patterns that can be used in other situations.
Rule-Based Systems: Logic that is clear in the field
Rule-based systems make decisions based on clear, logical rules. These rules are often based on what people who know a lot about the field know:
If the debt-to-income ratio is less than 0.35 and the credit score is over 750, you can approve the loan.
If your credit score is over 700, your debt-to-income ratio is less than 0.45, and you’ve been at the same job for at least two years, you can get a loan.
If your credit score is below 650, you can’t get a loan.
These systems are very easy to understand and check. But you need to know a lot about the topic to make the right rules. Rules often make things too simple, which makes models less accurate. As business needs change, it’s harder to keep up with and change rule systems.
A Complete List and Summary of XAI Methods
Post-Hoc Methods That Don’t Care About the Model: Making Black Boxes Clear
Model-agnostic methods are what we use when we need to explain the predictions of a complicated black-box model that we’ve already used. These methods work with any trained model, no matter how it’s built on the inside.
LIME (Local Interpretable Model-Agnostic Explanations)
The main idea behind LIME is that even if a complicated model’s decision boundary is very nonlinear overall, a simple model (like linear regression) can often do a good job of getting close to it in the area around a specific prediction we want to explain.
How LIME Works:
Perturbation: Change the values of some features at random while keeping the main structure the same to make thousands of slightly different versions of the input instance.
Get the black-box model’s guesses for each instance that has been changed.
Local Fitting: To fit these changed samples and their predictions, use a simple model, like linear regression.
The simple model that was fitted shows which features had the biggest impact on the prediction for the area.
Think of a sentiment analysis model that sorts a product review. LIME could randomly remove words from the review, see how the model’s sentiment score changes, and then fit a linear model to these links. The result shows that “terrible” and “broken” were the words that made people feel the worst, while “fast shipping” made people feel a little better.
The good things about LIME are:
It works with any model; it doesn’t care what kind it is.
Works fast: gives explanations in less than a second.
Intuitive visualizations: Bar charts that show how features work together are easy for people who aren’t tech-savvy to understand.
Local focus: It makes specific predictions without having to know about the whole world.
These are the limits of LIME:
Unstable: The results can change from one run to the next because of random perturbation sampling.
Only local view: Explanations don’t show how the model works in other places.
Concerns about fidelity: The linear approximation might not accurately show how the complex model works, which could lead to wrong explanations.
Assumption sensitivity: The results depend on how the perturbation is done; different perturbations can give different explanations.
SHAP: SHapley Additive Explanations
SHAP is based on the idea of cooperative games and works in a very strict way. It tells you how much each feature improves a prediction compared to a baseline, which is usually the average prediction across the training set.
The SHAP Concept:
Think of a game where the players are the features and the prize pool is the model’s prediction. How can the players split the prize fairly? The Shapley value is the average extra contribution of each player in all possible coalition orders, according to game theory.
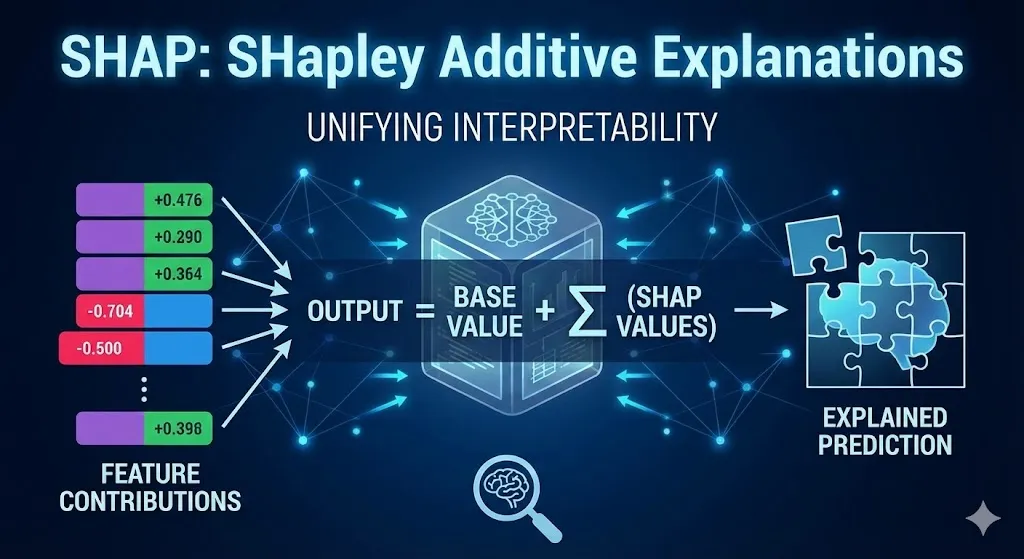
Image: SHAP value calculation example showing how different financial features add up to a final credit score of 530.
The good things about SHAP are:
It makes sense in theory because of well-known game theory and a mathematical proof.
A full view shows information on both the local (why this prediction?) and the global (which features are most important?) levels.
It is stable and reliable because you always get the same answers.
Finds interactions: It can find both straight and curved connections between features.
Ranking of feature importance: This feature automatically sorts features by how important they are to the model as a whole.
SHAP’s limits are:
When you have a lot of features, you have to use approximations because it takes a lot of computing power to find exact Shapley values.
Shapley values are hard for people who aren’t good at math to understand because they use complicated math.
Assumes model fidelity: If the model is biased, SHAP accurately describes that bias without changing it.
Runtime overhead: Real-time apps may not be able to handle the computing needs of SHAP.
When to Use LIME and SHAP: A Comparison
We should really think about which of these choices is best for us:
| When to choose LIME | When to choose SHAP |
| Some predictions in simple models need short, clear explanations. | You need to know how to use models that are hard to understand. |
| There aren’t a lot of computer resources. | For regulatory compliance and important decisions, it is very important that things stay the same and stable across multiple runs. |
| You want to know why certain things happen more than you want to understand the whole model. | You need both global and local explanations. |
| Stakeholders need to be able to talk to each other, so visualizations need to be easy to understand. | You want to know which parts of your model are the most important. |
| You’re making systems that need math-based explanations that can be repeated. |
XAI Giving Benefits in the Real World
When we look at how XAI is used in important areas of life, the theoretical benefits become clear.
Healthcare and Medical Diagnostics: How to Trust the Clinic
XAI is most useful in the field of healthcare. AI systems can now find cancers in medical images just as well as or even better than human radiologists. Radiologists, on the other hand, weren’t sure about these systems until XAI showed them how the algorithms worked.
XAI methods show exactly what parts of a mammogram made the AI system think there was something wrong with the tissue. A saliency map shows which parts of the picture the AI cared about the most. Doctors are more sure if these areas show signs of carcinoma, like mass characteristics, microcalcifications, or changes in the structure of the tissue. If the AI points out shadows or artifacts that aren’t dangerous, doctors know right away that something is wrong.
For example, diagnostic accuracy is something that happens in real life.
Hospitals that use XAI diagnostic systems say they work much better. AI-assisted administrative tasks helped AtlantiCare cut down on paperwork for each provider by 66 minutes a day. Doctors can give more specific treatments when they can understand AI suggestions, which is more important. This makes it more likely that patients will stick to their treatment plans.
Research indicates that XAI in healthcare can enhance treatment outcomes by as much as 30% for patients with multiple chronic conditions by providing clear, individualized recommendations that consider all of their conditions simultaneously.
The effect goes beyond just tests to include medicine that can tell you what will happen. AI systems that look at electronic health records can now find people who are more likely to get diseases like Alzheimer’s and diabetes. When these predictions are clear—”the patient’s cognitive decline trajectory matches early Alzheimer’s patterns based on neuropsychological test trends”—clinicians can take preventive measures sooner, which could stop the disease from getting worse.
Money saved and how it affects operations
The effects on money are big. According to the RAND Corporation, using XAI to mix AI with human knowledge could save the U.S. healthcare system up to $150 billion a year. This is because diseases are found earlier, people spend less time in the hospital, treatment is better planned, and there are fewer bad things that happen because decisions are clear and can be checked.
Financial Services: Following the rules and treating customers fairly
XAI is a must-have for businesses because finance is probably the most regulated area for AI applications.
Giving Clear Credit
People who apply for credit must be told why they were turned down by banks. The Fair Credit Reporting Act and other laws like it say that people have the right to know why they were turned down for credit. Regulatory liability exists because conventional black-box models are incapable of providing such explanations.
XAI makes it easy to see how credit decisions are made. Now, if a bank turns down a loan application, they can say, “The decision was mostly based on your debt-to-income ratio of 0.52 (which is higher than our acceptable threshold of 0.45) and your credit utilization rate of 89%. Your credit history and job stability are both strong reasons for approval.”
There are many good things about being open. People who are looking for work know exactly what changes would change the decision, such as lowering their debt or use. The bank keeps track of how it makes decisions to show that it follows the rules and is fair. The best thing about XAI analysis is that it quickly shows if the model is unfair, like if certain zip codes are unfairly turned down for credit. This helps you fix the problem.
Finding fraud: How to find the right balance between safety and trust from customers
Every day, banks and other financial institutions look at millions of transactions and mark any that seem fake for more investigation. Customers get angry when there are false positives because they stop real transactions and have to call customer service for help.
Big banks have been able to lower the number of false positives by up to 30% thanks to better fraud detection with XAI. They have also been able to keep or even raise their fraud detection rates. The analysts can tell the difference between real fraud and legitimate anomalies because they know what features trigger fraud alerts.
For instance, if a customer does something that seems strange, their transaction could be marked as suspicious.
The customer doesn’t usually go to the place where the transaction takes place.
The deal is worth a lot more than usual.
This customer doesn’t usually shop at stores like this.
XAI analysis might show that the location difference alone, which is common for travelers, shouldn’t set off alarms. Fraud analysts can make better rules if they know how features help fraud. This catches real fraud while lowering the number of false positives.
How to Find and Fix Algorithmic Bias in the Criminal Justice System
One of the biggest problems with AI is that some systems are biased, which hurts people’s freedom and fairness. This problem is solved in the criminal justice system with the help of XAI.
Risk assessment algorithms help find out which criminals are most likely to do something bad again. This information is used to figure out how much bail and parole should cost. Researchers used XAI methods (LIME) on the popular COMPAS system and found a lot of racial bias: Black defendants had false positive rates that were 2.5 times higher than those of white defendants.
This finding would have been nearly impossible without XAI. The model that wasn’t clear made guesses, but it didn’t explain why those guesses were different for people of different races. XAI made the bias clear, which helped researchers write down the issue and got more people interested in how fair algorithms are.
XAI is always looking for bias in modern uses. XAI analysis shows what factors led to each choice when a risk assessment system makes suggestions. If things like a person’s past arrests, which show that policing is unfair instead of that they are a criminal, are the main things that affect decisions, it is clear that bias exists and can be acted on.
Autonomous Systems: Safety by Being Clear
XAI is used by companies that make self-driving cars to make sure the cars are making the right decisions. XAI tells you why a self-driving car suddenly stops or changes lanes: “Obstacle detected at 15 meters; initiating avoidance maneuver.” This level of openness lets manufacturers check that cars are responding correctly to dangers and find possible failure modes before they cause accidents.
The Accuracy-Interpretability Trade-Off: A Hard Truth
XAI always has to find a way to make models that are both accurate and easy to understand. Because they can find nonlinear relationships, complex models are better at making predictions. But this makes them harder to understand. Simple, clear models are easy to understand, but they don’t always give the right answer. Is this trade-off really needed?
The answer isn’t simple: how bad the trade-off is depends on the problem area and the models being compared.
In some places, there are models that are both very accurate and easy to understand. Gradient-boosted trees are better for data that looks like a spreadsheet with rows and columns, and they are easier to understand than deep neural networks. Microsoft’s Explainable Boosting Machines (EBMs) are a newer way that gives up some accuracy in exchange for much better interpretability. They are completely honest about how they work and get 98–99% of the accuracy of neural networks.
The gap is bigger in other areas. Neural networks can pick up on patterns that aren’t linear or hierarchical, which is why deep learning is so good at understanding natural language, recognizing speech, and recognizing images. A deep learning model that can find tumors in medical images with 98% accuracy could turn into a decision tree with only 93% accuracy, which is a big drop in accuracy. In these cases, businesses need to think about whether the loss of accuracy is worth the gain in ease of understanding.
But this way of thinking misses an important point: accuracy is only one thing that makes a model good. A model that unfairly denies loans to some people doesn’t matter how accurate it is. A clear model that is a little less accurate and stops this kind of bias might be better. A model that is very accurate but hard to understand and that doctors don’t trust might not work as well in the real world as a model that is a little less accurate but that doctors use with confidence.
Advanced XAI Techniques: Feature Importance Is Not Everything
LIME and SHAP are the most popular methods right now, but new ones that explain things better are coming out all the time.
You can find out how important a feature is by randomly moving it around and seeing how performance drops. If changing that feature doesn’t make the model work better, then it’s not important. If it does, that feature is very important. This method is easy to understand and works with any model.
PDPs (Partial Dependence Plots) and ICE Curves (Individual Conditional Expectation Curves) show how the model’s predictions and the input’s features are related. A PDP shows how changing one feature changes the average of the whole dataset, while an ICE curve shows how this works for each individual case. These tools can help you figure out if the relationships between features are linear, nonlinear, or have interactions that aren’t what you expect, which could mean the model is wrong.
Image and text models need Saliency Maps and Attention Visualization. Saliency maps help image classifiers figure out which pixels had the most effect on a classification. If an image classification model says “dog,” it might show saliency that is mostly on the face. Attention visualization shows how transformer models in NLP made decisions based on words.
Counterfactual Explanations is a new area of research. For instance, “The loan would have been approved if your credit score had been 50 points higher.” These explanations are inherently actionable; they tell stakeholders exactly what needs to change to change decisions. Research into causal counterfactual explanations may link correlations identified by models to genuine causal relationships.
Problems and Limitations: A Fair Evaluation
XAI could make things better, but it also has a lot of problems that people who use it need to know about.
The Fidelity Problem: A straightforward description of how the model functions may be inaccurate. LIME is meant to make a local linear approximation that might not be a good representation of how the real model works. People might think they know more than they do if explanations don’t really show how the model works.
SHAP and other methods that use a lot of computer power make it hard to explain things in real time for apps that have a lot of data. A fraud detection system must elucidate alerts within milliseconds, whereas SHAP’s complexity may require seconds.
There are no set rules for how to tell if XAI is good or bad. Different tools give different reasons for the same model, and people who want to know if those reasons are true can’t do anything about it. This makes things less clear and hurts XAI’s trustworthiness.
User-Centric Challenges: There isn’t one way to explain things that works for everyone. A data scientist, a compliance officer, and a patient all need different kinds of explanations for the same choice. It’s still hard to make XAI systems that can change explanations based on what someone knows.
XAI can show biases, but it can’t get rid of them on its own. No matter how you explain how biased decision-making works, it is still biased decision-making. XAI can find bias, but fixing it takes more work on both the technical and organizational sides.
New Trends: The Future of AI That Can Be Explained
There are a lot of big trends in the XAI field that are changing how things work.
Neuro-Symbolic AI: Designed to be Understandable
Researchers are now working on systems that are easy to understand from the start, instead of models that are hard to understand after the fact. Neuro-symbolic AI is a kind of AI that combines neural networks with symbolic reasoning. This means that it uses the ability of deep learning to find patterns and the clarity of symbolic logic.
Neural networks could be used by a neuro-symbolic system to process raw sensor data like audio, text, and images. Then, it could use symbolic reasoning to come to a conclusion. This mixed method keeps the accuracy benefits of neural networks while also making it easier to make decisions by using symbolic reasoning.
For instance, a neuro-symbolic diagnostic system in healthcare uses deep learning to look at medical images very accurately. Then, it uses symbolic reasoning to say, “If tumor detected AND tumor size > 3cm AND located in critical region THEN recommend urgent surgical intervention.” Clinicians can trust the neural network’s detection because it is accurate, and they can check the recommendation against medical guidelines.
The best part is that we make the system architecture clear from the start instead of adding it later. Stanford and MIT are working on ways to combine symbols and neurons. These show that these mixed systems can be completely clear and still keep 94% of the accuracy of a pure neural network.
Hypothetical and causal elucidations
XAI is moving away from models that only show correlations and toward causal explanations that show real cause-and-effect links. A correlation-based explanation says, “The credit score was the reason the loan was denied.” A causal explanation says, “The credit score was the reason the loan was denied, not because it stood in for something else.”
Counterfactual explanations exemplify this boundary: “If your credit score had been 50 points higher, the loan would have been approved.” These explanations are intrinsically actionable and correspond with human reasoning. New research on causal inference is making it easier to explain things like this.
XAI and MLOps work well together.
XAI is no longer just a way to look at things after they have been used; it is now a part of how things work. Modern Machine Learning Operations (MLOps) frameworks use XAI at every stage of a model’s life cycle. It is used to find bugs and biases while the software is being developed, to give explanations in real time while it is being used, and to find drift and look at performance while it is being monitored.
Two platforms that use XAI to watch models are Aporia and Fiddler AI. This lets them explain things right away and find bias in production settings on their own.
As a driver, following the rules
Regulatory requirements are pushing for XAI to be the same across the board. The EU AI Act says that AI systems that are very dangerous need to be clear. XAI has to follow the law because the GDPR says that companies have to be open. Companies need to make sure that their AI systems can explain themselves in a way that is legal as rules become law. This will make XAI tools and methods more useful and popular.
The XAI Environment: Platforms and Tools
Businesses that want to use XAI have a lot of choices. We think about the best ways to do things:
| Type of Tool/Platform | Best For | Strengths | Weaknesses | Main Industries |
| SHAP | Building complex models and getting deep insights | Makes sense theoretically, works globally & locally, stable. | Costs a lot to run, harder to learn. | Technology, Healthcare, Finance |
| LIME | Local explanations, simple models, fast results | Open-source, works with any model, quick, easy to understand. | Only local view, unstable results, issues with complex boundaries. | Marketing, E-commerce, Fraud Detection |
| InterpretML (Microsoft) | Interpretable models + explanation | Open-Source + Cloud; High accuracy with interpretability (EBMs). | Requires Azure for full functionality. | Finance, Insurance, Enterprise |
| IBM Watson OpenScale | Enterprise Platform, documentation, monitoring | Real-time monitoring, compliance tracking, supports multiple frameworks. | Costs more, vendor lock-in, hard to set up. | Finance, Insurance, Regulation |
| Google Cloud Explainable AI | Cloud service for tables, images, text | Works well with Vertex AI, scalable, ready to use. | Only works with Google Cloud. | General Tech, Cloud Services |
| Aporia | Enterprise SaaS, Real-time monitoring | Supports all ML frameworks, bias/drift detection. | Costs a lot, needs infrastructure. | B2B SaaS, Finance, Technology |
| TreeInterpreter | Tree-based models (Random Forest, XGBoost) | Free, easy to use, works quickly. | Only works with tree-based models, doesn’t explain generally. | Finance, Healthcare, Insurance |
FAQ’s
1. What is the main difference between a black-box model and an AI system that can be explained?
Deep neural networks and other black-box models can be very accurate, but it’s hard to figure out why they make the predictions they do because we can’t see how they make decisions. Explainable AI systems either use models that are easy for people to understand, like decision trees, or they use ways to explain black-box models so that people can understand how they came to their conclusions. The main difference is how easy it is to understand: can we follow and check how the decision was made?
2. If my model is very accurate, why should I care about XAI?
A model’s quality isn’t just based on how accurate it is. High accuracy doesn’t mean much if the model is biased and regulators won’t approve it or users won’t trust it. Doctors in the healthcare field might not follow a very accurate diagnosis recommendation if they don’t know why it was made. In finance, lending decisions that aren’t clear can get you in trouble with the law. Unexplained risk scores in the criminal justice system cause unfair results. XAI lets accuracy have an effect on the real world by being open, following the rules, and building trust.
3. What are the different kinds of XAI techniques, and how do they differ from each other?
There are three main types of XAI methods. Intrinsic interpretability makes models that are easy to understand from the start, like linear regression and decision trees. LIME and SHAP are two ways to explain black-box models that have already been trained. They work with any model. Post-hoc methods that look at a model’s results include feature importance and saliency maps. They cost different amounts to run, explain things in different ways (locally vs. globally), and follow the rules of theory in different ways. What you need will help you pick the best choice.
4. What makes SHAP and LIME different from each other, and which one should I use?
LIME gives quick, local explanations that work well for some predictions in simpler models. SHAP is more expensive to run, but it gives better, more mathematically sound explanations from both a local and a global point of view. For tasks that aren’t very important, LIME is a quick and easy way to explain things. SHAP can help you understand a model better, follow the rules, or make big decisions. A lot of businesses use both LIME and SHAP in real life: LIME for initial insights and SHAP for strict validation.
5. Are simple models just as good as complicated black-box models?
Sometimes, but not all the time. Explainable Boosting Machines and other new methods are 98–99% as accurate as neural networks, but they are still easy to understand for data in tables. For harder tasks, like recognizing images or understanding natural language, the difference in accuracy is bigger. But the question doesn’t always get to the heart of the matter. We should ask, “What mix of accuracy, interpretability, fairness, and following the law best fits our real business needs?” A model that is 94% accurate and clear is often better than one that is 98% accurate and not clear.


Pingback: Implementing Responsible AI from Day One: A Comprehensive Framework for Building Trustworthy AI Systems - Bing Info
Pingback: The AI Trend That Got the Most Hype in 2025 (and the One That Got the Least) - Bing Info