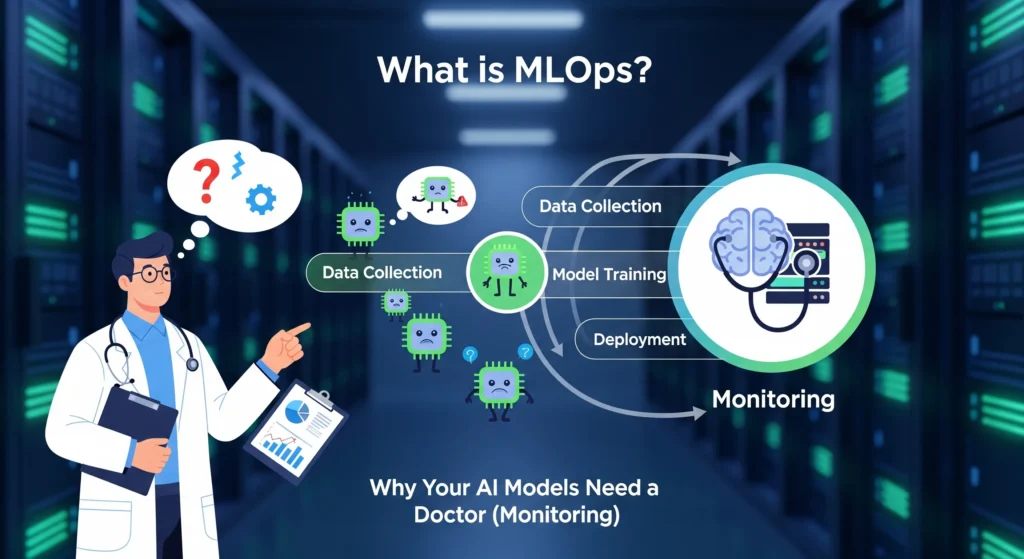
What is MLOps? Why Your AI Models Need a Doctor (Monitoring)
You’ve built an incredible AI model. It predicts customer behavior with 94% accuracy. Your team celebrates. Six months later? That same model is making predictions so wild that your business team stopped trusting it completely.
Sound familiar?
You’re not alone. Here’s the kicker: 67% of AI models never even make it to production, and for those that do, 91% experience performance degradation over time. It’s like training a doctor who gradually forgets medicine.

That’s where MLOps comes in—think of it as regular health checkups for your AI models. And trust me, your models need them.
In this post, we’re diving deep into what MLOps actually is, why monitoring your models is non-negotiable, and how you can stop your AI from slowly losing its mind. By the end, you’ll understand exactly why your machine learning models need constant supervision (yes, just like toddlers) and what happens when they don’t get it.
Let’s get started.
Understanding MLOps: The Basics
MLOps stands for Machine Learning Operations. If that sounds boring, stick with me—because what it does is anything but.
Think of MLOps as the bridge between building cool AI models in notebooks and actually using them in real businesses. It’s what happens after the data scientist says “my model works!” and before customers actually benefit from it.

Here’s the simple version: MLOps combines machine learning (the AI part), software engineering (the building part), and data engineering (the data part) into one smooth workflow. The term was actually coined back in 2015 in a research paper about “hidden technical debt in machine learning systems”. Turns out, building models is the easy part. Keeping them working? That’s the challenge.
What MLOps Actually Does
MLOps isn’t just one thing—it’s a whole set of practices that cover the entire life of your machine learning model. From the moment you collect data to train your model, all the way through deployment and continuous monitoring, MLOps keeps everything running smoothly.
The ML lifecycle typically includes these stages:
Data Collection and Preparation – Gathering and cleaning data so it’s actually usable
Model Training and Testing – Building your model and making sure it works
Model Deployment – Getting your model into production where real users interact with it
Model Monitoring – Watching how your model performs over time (this is the crucial part everyone forgets)
Model Updates and Improvements – Retraining and updating when performance drops
`
Before MLOps existed, each of these steps was manual, slow, and prone to breaking. Data scientists would build amazing models on their laptops, then hand them off to engineering teams who had no idea how to deploy them. Weeks (or months) would pass before anything actually worked in production.
MLOps automates all of this. It creates assembly lines for machine learning, turning what used to take months into days or even hours.
MLOps vs DevOps: What’s the Difference?
You’ve probably heard of DevOps. So is MLOps just DevOps with a fancy ML twist?
Not quite.
While MLOps builds on DevOps principles, they’re solving different problems. DevOps focuses on shipping software applications quickly and reliably. MLOps? It’s all about shipping and maintaining machine learning models, which are way more complicated.
Here’s why ML models are different animals:
They’re data-centric, not just code-centric. A software application is basically a set of instructions. An ML model is those instructions plus the data it learned from plus the statistical relationships it discovered. Change the data, and the whole model might need retraining.
They drift over time. Your web application doesn’t suddenly start performing worse because the world changed. Your ML model absolutely does. Customer behavior shifts, markets evolve, and suddenly your fraud detection model is missing new types of fraud.
Artifacts are dynamic, not static. In DevOps, you version your code and configuration files. In MLOps, you also need to version datasets, model parameters, experiment results, training configurations, and the actual trained models themselves. It’s version control on steroids.
Testing is different. In DevOps, you test whether your code works. In MLOps, you test whether your model is accurate, whether it’s biased, whether the data has drifted, whether predictions are stable, and a dozen other things.
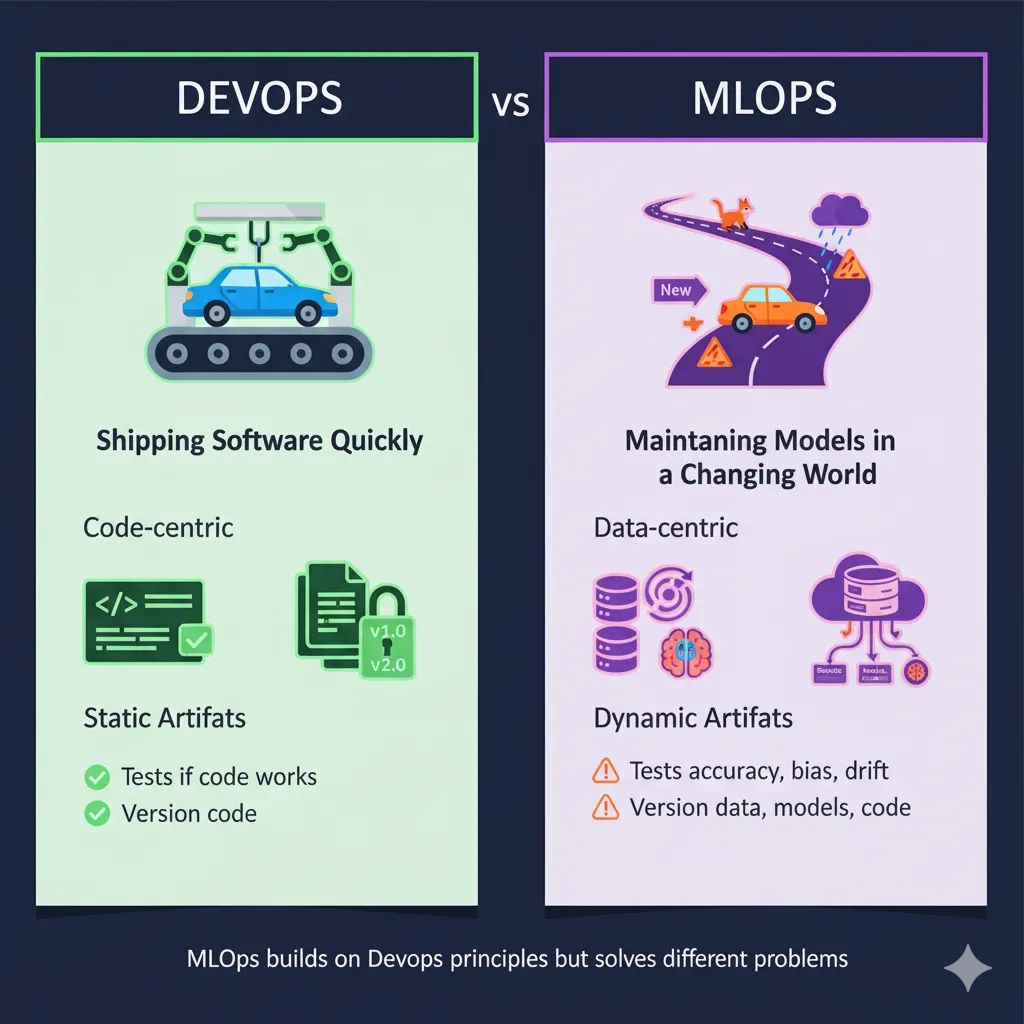
Think of it this way: DevOps builds the car. MLOps builds the self-driving system inside the car—which needs constant updates as roads change, traffic patterns shift, and new obstacles appear.
The good news? MLOps borrows the best practices from DevOps—like continuous integration, continuous deployment (CI/CD), and automated testing—then extends them to handle the unique challenges of machine learning.
The MLOps Pipeline: How It All Works
Okay, so how does this all fit together in practice?
An MLOps pipeline is the automated workflow that takes your model from training to production. Instead of manually copying files and crossing your fingers, you build a system that handles everything automatically.
Here’s what a typical MLOps pipeline looks like:

Stage 1: Data Collection and Validation
First, you need data. But not just any data—clean, validated, high-quality data.
The pipeline automatically collects data from databases, APIs, or files. Then it runs validation checks: Are there missing values? Outliers? Does the data distribution look normal? If something’s wrong, the pipeline alerts you before wasting time training a bad model.
Tools like Apache Airflow can schedule these data collection tasks to run automatically.
Stage 2: Model Training and Experiment Tracking
Once your data passes validation, the pipeline trains your model.
But here’s where MLOps shines: it tracks everything. Every hyperparameter you tried. Every accuracy score. Every version of the model. Tools like MLflow and Neptune keep detailed logs so you can compare experiments and pick the best model.
Stage 3: Model Testing and Validation
Before deployment, automated tests check if the model meets your performance standards. Is accuracy above your threshold? Does it handle edge cases? Is there bias in predictions?
If the model fails these tests, it doesn’t move forward. No more “oops, we deployed a broken model to production.”
Stage 4: Automated Deployment
Once the model passes all tests, the pipeline automatically deploys it to production.
This might involve containerizing the model with Docker, deploying it to Kubernetes, or pushing it to cloud services like AWS SageMaker or Google Vertex AI. The key is that it happens automatically, without someone manually copying files around.
Stage 5: Continuous Monitoring
Here’s where the magic really happens—and where most teams fail.
After deployment, the pipeline continuously monitors your model. It tracks:
Model performance metrics (accuracy, precision, recall)
Data drift (are inputs changing?)
Concept drift (are relationships changing?)
System health (latency, errors, resource usage)
When something goes wrong, automated alerts notify your team. Maybe accuracy dropped below 90%. Maybe the model started seeing data patterns it never trained on. Maybe latency spiked to 5 seconds.
Stage 6: Automated Retraining
When monitoring detects problems, the pipeline can automatically trigger retraining.
New data gets collected, the model retrains on fresh information, tests run automatically, and if everything passes, the new model deploys to production. All without manual intervention.
This continuous cycle—train, deploy, monitor, retrain—is what separates successful MLOps implementations from failed ones.
Why Your AI Models Need Monitoring (Spoiler: They’re Not Set-and-Forget)
Here’s a hard truth: building an ML model is maybe 10% of the work. The other 90%? Keeping it working in production.
Most data scientists think their job ends when the model hits production. Wrong. That’s when the real challenges begin.
The Shocking Reality of AI Model Failure
The statistics are brutal:
Only 54% of AI projects make it from pilot to production
87% of AI projects never reach production at all
91% of models that do deploy experience performance degradation
95% of generative AI implementations at companies are failing

Why do so many models fail? It’s not because data scientists are bad at their jobs. It’s because nobody’s watching what happens after deployment.
What Happens When Models Go Unmonitored
Let me paint you a picture of what model degradation looks like.
You train a fraud detection model in January. It works great—catching 95% of fraudulent transactions. By June, it’s only catching 70%. What happened?
Fraudsters evolved. They changed their tactics. Your model never saw these new patterns during training, so it can’t detect them. This is called concept drift—when the relationship between inputs and outputs changes over time.
Or maybe the data itself changed. Your e-commerce recommendation model trained on data from 20-year-olds. Six months later, your user base skews older. Same model, different data distribution. That’s data drift, and it’ll tank your model’s performance.
Here’s a real example: researchers found that medical imaging models trained five years ago perform significantly worse on modern imaging equipment. The technology improved, but the models didn’t adapt.
The Cost of Ignoring Model Health
When models degrade and nobody notices, bad things happen:
Financial losses – A bank’s credit scoring model starts approving risky loans. Millions in losses before anyone realizes the model drifted.
Customer churn – Your recommendation system stops suggesting relevant products. Customers get frustrated and leave.
Regulatory violations – Healthcare diagnostic models make inaccurate predictions. Patients receive wrong treatments. Lawsuits follow.
Reputational damage – Your AI chatbot starts giving nonsensical responses. Screenshots go viral on social media. Brand trust plummets.
The scary part? These degradations often happen slowly. You don’t notice the model getting 1% worse each week. But over six months, that’s a 24% performance drop.
How Monitoring Saves Your Models
Continuous monitoring catches problems before they become disasters.
Good monitoring tracks multiple signals simultaneously:
Model Performance Metrics – Accuracy, precision, recall, F1 score. Are predictions still correct?
Data Quality Checks – Missing values, outliers, data type mismatches. Is the input data valid?
Drift Detection – Statistical tests comparing current data to training data. Has the data distribution changed?
System Health – Latency, throughput, error rates, resource usage. Is the infrastructure holding up?
Business Impact – Click-through rates, conversion rates, revenue. Is the model actually helping the business?

When any of these metrics crosses a threshold, you get alerted immediately. Maybe data drift just jumped 40%. Maybe average latency went from 100ms to 2 seconds. Maybe accuracy dropped below your baseline.
With monitoring, you catch the problem when accuracy drops to 92%—not when it hits 70% and customers are already complaining.
Model Drift: The Silent Killer
If monitoring is the doctor’s checkup, drift is the disease your models catch over time.
There are two main types you need to know about:

Concept Drift: When Relationships Change
Concept drift happens when the statistical relationship between your inputs (X) and outputs (Y) changes.
Think about spam detection. In 2010, spam emails screamed “CLICK HERE TO WIN” with terrible grammar. Your model learned to catch those. Fast forward to 2025? Spammers use sophisticated phishing tactics with perfect grammar, personalised content, and legitimate-looking sender addresses.
The definition of spam changed. Your model’s understanding didn’t.
Concept drift can be:
Sudden – Stock market crashes, pandemics, major policy changes. The world shifts overnight.
Gradual – Consumer preferences slowly evolve. Old concepts fade while new ones emerge.
Recurring – Seasonal patterns like retail sales spikes during holidays.
Data Drift: When Inputs Change
Data drift (also called covariate drift) occurs when the distribution of input features changes, even if the underlying relationships stay the same.
Your model trained on data from users aged 18-25. Now your user base is 30-45. Same behaviors, different demographics. The model struggles because it never learned patterns from this age group.
Here’s a real-world example: during COVID-19, almost every predictive model broke. Commute patterns changed, shopping behaviors shifted online, job categories transformed. The data looked nothing like what models trained on.
Detecting Drift Before It’s Too Late
Good MLOps platforms include drift detection tools that automatically compare your current data to your training data.
They use statistical tests like:
Kolmogorov-Smirnov test – Compares distributions
Population Stability Index (PSI) – Measures shifts in data populations
KL Divergence – Quantifies differences between probability distributions
When drift exceeds a threshold (say, PSI > 0.25), alarms go off. Your team investigates. Maybe you need to retrain on fresh data. Maybe you need to adjust feature engineering. Maybe you need a completely new model architecture.
The key is catching drift before it destroys model performance. Monitoring gives you that early warning system.
Real-World MLOps Examples
Theory is nice, but let’s see how real companies actually use MLOps to keep their AI running.
Netflix: Recommendations at Scale
Netflix serves over 230 million subscribers with personalized content recommendations. Every single recommendation comes from ML models.
Their MLOps challenge? Managing thousands of models simultaneously. Each model needs training, testing, deployment, and monitoring.
Netflix built their own MLOps platform called Metaflow. It handles:
Automated experiment tracking across all model versions
Parallel training of multiple models
Continuous monitoring of recommendation quality
Automated retraining when model performance degrades
Result? Users see relevant recommendations in real-time, and Netflix maintains incredibly high engagement rates.
Uber: Real-Time Predictions
Uber relies on ML for everything—dynamic pricing, route optimization, fraud detection, food delivery predictions.
They built Michelangelo, an end-to-end MLOps platform. It provides:
Feature stores for consistent data across all models
Automated model deployment to production
Real-time monitoring of prediction latency and accuracy
A/B testing frameworks to compare model versions
The platform handles millions of predictions per second. Without robust MLOps, Uber’s entire business would grind to a halt.
Airbnb: Data Quality at Scale
Airbnb processes over 50GB of data daily to power their ML models. Their challenge? Ensuring data quality while moving fast.
Their MLOps solution includes:
Automated data validation pipelines using Apache Airflow
Near real-time data processing on AWS EMR
Continuous model performance monitoring
Automated retraining when data patterns shift
The result? Improved recommendation match rates, better pricing models, and higher guest-host connection rates.
What These Companies Have in Common
Notice the patterns:
Automation everywhere – No manual model deployments. Everything automated through pipelines.
Continuous monitoring – Models watched 24/7 for performance, drift, and system health.
Feature stores – Centralized data management so all models use consistent features.
Automated retraining – When performance drops, models automatically retrain on fresh data.
Experimentation tracking – Every model version logged for reproducibility.
These companies succeed because they treat models like products that need constant care—not one-time projects you “finish” and forget about.
Essential MLOps Tools for 2025
Building your own MLOps platform from scratch is possible (like Netflix and Uber did) but unnecessarily hard. Plenty of great tools exist to get you started.
Here are the most important categories:

End-to-End MLOps Platforms
These handle the entire ML lifecycle in one place:
AWS SageMaker – Amazon’s fully managed platform. Great if you’re already in AWS. Handles training, deployment, and monitoring with built-in drift detection.
Azure Machine Learning – Microsoft’s offering. Excellent integration with other Azure services. Strong governance features for enterprises.
Google Vertex AI – Google Cloud’s unified platform. Fantastic for teams using TensorFlow. AutoML capabilities for rapid prototyping.
Databricks – Great for teams already using Apache Spark. Strong data engineering capabilities alongside ML.
Model Monitoring and Observability
These specialize in watching deployed models:
Arize AI – Comprehensive monitoring platform. Excellent drift detection, root cause analysis, and explainability features.
WhyLabs – AI observability focused on data quality and model health. Lightweight and cost-effective.
Evidently AI – Open-source monitoring library. Great for teams wanting customization. Generates interactive dashboards.
Fiddler AI – Strong explainability features. Helps understand why models make specific predictions.
Experiment Tracking
These log every experiment so you can reproduce results:
MLflow – Open-source standard for experiment tracking. Simple to set up, widely adopted.
Neptune – Enterprise-grade experiment tracking with great visualization. Handles thousands of metrics.
Weights & Biases – Popular in deep learning. Great visualization and collaboration features.
Pipeline Orchestration
These automate ML workflows:
Kubeflow – Kubernetes-native ML workflows. Best for teams already using Kubernetes.
Airflow – General-purpose workflow orchestration. Excellent for complex data pipelines.
AWS Step Functions – Serverless workflow orchestration on AWS. Pay only for what you use.
Model Deployment
These get models into production:
Seldon Core – Open-source model deployment on Kubernetes. Supports advanced deployment strategies like canary and A/B testing.
BentoML – Package and deploy models as APIs. Simple developer experience.
TorchServe – PyTorch model serving. Optimized for PyTorch models specifically.
Picking the Right Tools
Don’t try to use every tool. Start simple:
For startups and small teams: Start with MLflow (experiment tracking) + Evidently AI (monitoring) + your cloud provider’s deployment service. All free or cheap.
For mid-size companies: Add Apache Airflow (orchestration) + Seldon Core (advanced deployment). More power, still manageable costs.
For enterprises: Consider full platforms like AWS SageMaker, Azure ML, or Databricks. Yes, they’re expensive, but they handle everything and scale infinitely.
The best tool is the one your team actually uses. Pick something, start monitoring your models, and iterate from there.
MLOps Best Practices: What Actually Works
Okay, you’re convinced MLOps matters. Now what? Here are the practices that separate successful implementations from expensive failures:

Start Monitoring Early (Like, Day One Early)
Don’t wait until deployment to think about monitoring. Start during development.
Track metrics from your first experiment. Log everything—hyperparameters, training data stats, validation scores. This creates baselines you’ll need later to detect drift.
Why this matters: You can’t know if your model degraded unless you know how it performed originally.
Define Clear Success Metrics
“Make the model better” isn’t a goal. “Maintain 95% accuracy with under 100ms latency” is.
Define specific, measurable metrics aligned with business objectives:
Model-specific: accuracy, precision, recall, F1 score
Operational: latency, throughput, error rate
Business: revenue impact, customer satisfaction, conversion rate
Get stakeholders to agree on these upfront. When accuracy drops to 93%, you need clear thresholds for action.
Automate Everything You Can
Manual processes don’t scale.
Automate:
Data validation before training
Model testing before deployment
Deployment to production
Monitoring and alerting
Retraining when performance drops
Yes, automation takes time to set up. But it saves exponentially more time long-term.
Set Up Intelligent Alerts
Getting 1,000 alerts per day means you’ll ignore all of them.
Configure alerts that are:
Actionable – Clear next steps when triggered
Contextual – Enough information to diagnose quickly
Prioritized – Critical issues separate from minor warnings
Example good alert: “Customer churn model accuracy dropped to 88% (threshold: 90%). Data drift detected in ‘purchase_frequency’ feature. Recommended action: investigate feature distribution and schedule retraining.”
Build a Troubleshooting Framework
When alerts fire, your team needs a playbook.
Document common issues and solutions:
Data drift → Check data pipeline for changes → Retrain on recent data
Concept drift → Review business changes → Update model architecture
System performance → Scale infrastructure → Optimize model size
Train your team on this framework before problems happen.
Version Everything
Code. Data. Models. Configurations. Everything.
Use tools that automatically track versions:
Git for code
DVC for data versioning
MLflow or Neptune for model versioning
When something breaks, you can roll back to the last working version instantly.
Foster Cross-Team Collaboration
MLOps fails when data scientists, ML engineers, and ops teams work in silos.
Successful teams:
Meet regularly to discuss model performance
Share monitoring dashboards openly
Involve ops teams in model design decisions
Train data scientists on deployment challenges
The best models come from teams that actually talk to each other.
Embrace Continuous Learning
Your first MLOps setup won’t be perfect. That’s okay.
Regularly review:
Which metrics actually matter?
Are alerts too noisy or too quiet?
Is retraining happening at the right frequency?
What’s the biggest bottleneck?
Iterate. Improve. Repeat.
The MLOps Career Path
Curious about becoming an MLOps engineer? It’s one of the hottest careers in tech right now.
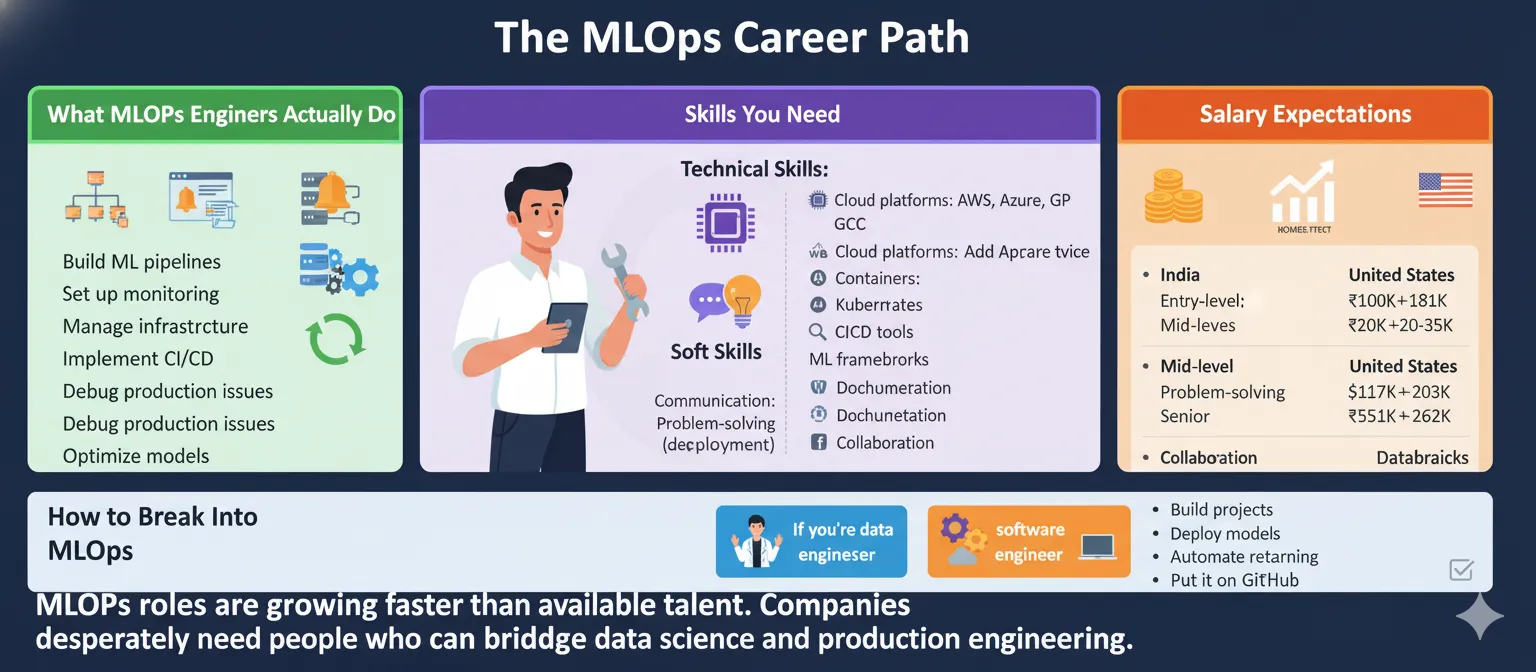
What MLOps Engineers Actually Do
MLOps engineers sit between data science and software engineering. They:
Build ML pipelines that automate training and deployment
Set up monitoring systems to track model health
Manage infrastructure for training and serving models
Implement CI/CD processes for ML workflows
Debug production issues when models fail
Optimize models for performance and cost
It’s part DevOps, part data engineering, part software engineering.
Skills You Need
Technical skills:
Cloud platforms: AWS, Azure, or GCP (pick one, master it)
Containers: Docker and Kubernetes
CI/CD tools: Jenkins, GitHub Actions, GitLab CI
Programming: Python (mandatory), bash scripting
ML frameworks: TensorFlow, PyTorch, scikit-learn
Orchestration: Airflow, Kubeflow, or Prefect
Monitoring: Prometheus, Grafana, ELK stack
Soft skills:
Communication between technical and business teams
Problem-solving under pressure
Documentation (seriously, document everything)
Collaboration across disciplines
Salary Expectations
MLOps engineer salaries are competitive:
India:
Entry-level (0-2 years): ₹6-10 lakhs per year
Mid-level (2-5 years): ₹10-20 lakhs per year
Senior (5+ years): ₹20-35 lakhs per year
Tech hubs like Bangalore and Hyderabad pay more
United States:
Entry-level:
100K−100K-181K per year
Mid-level:
117K−117K-203K per year
Senior:
151K−151K-262K per year
Silicon Valley and NYC pay premium salaries
The average globally is around
94K−94K-120K, but specialization in cloud platforms, advanced ML, and at-scale deployment can push this much higher.
How to Break Into MLOps
If you’re a data scientist: Learn Docker, Kubernetes, and cloud platforms. Start deploying your own models to production. Practice setting up monitoring.
If you’re a DevOps engineer: Learn ML basics—how models train, evaluate, and predict. Understand what makes ML different from regular software. Take an ML course.
If you’re a software engineer: Learn data engineering, ML frameworks, and experiment tracking. Build end-to-end projects that go beyond “train a model in a notebook.”
For everyone: Build projects. Deploy models to cloud platforms. Set up monitoring dashboards. Automate retraining. Document everything. Put it on GitHub.
MLOps roles are growing faster than available talent. Companies desperately need people who can bridge data science and production engineering.
Common MLOps Challenges (And How to Overcome Them)
Let’s be real: implementing MLOps isn’t easy. Here are the roadblocks you’ll hit—and how to get around them.
Challenge 1: Data Quality and Availability
The problem: Garbage in, garbage out. Models trained on bad data produce bad predictions.
Issues include:
Missing values
Inconsistent formats
Outdated data
Insufficient volume
Lack of labeled data
Biased training sets
The solution:
Implement automated data validation pipelines
Set up data quality monitoring with tools like Great Expectations
Create data versioning systems with DVC
Establish clear data labeling processes
Build diverse, representative datasets
Don’t skip data quality checks. They prevent model failures before they happen.
Challenge 2: Model Complexity and Scalability
The problem: Models that work on your laptop fail at scale.
What works with 1,000 predictions per day breaks at 1 million.
The solution:
Design for scale from day one
Use cloud infrastructure that auto-scales
Optimize model size (smaller often works better in production)
Implement caching for frequent predictions
Consider model distillation for resource-intensive models
Test your models under realistic load before deployment.
Challenge 3: Lack of Cross-Functional Collaboration
The problem: Data scientists build models in isolation. Engineers have no idea how to deploy them. Ops teams don’t understand ML requirements.
Communication gaps cause 90-day deployment timelines.
The solution:
Create cross-functional MLOps teams from the start
Have regular sync meetings between DS, engineering, and ops
Share monitoring dashboards across teams
Involve engineers early in model design
Train data scientists on deployment considerations
Break down silos. Make MLOps a team sport.
Challenge 4: Tool Proliferation and Integration
The problem: You’ve got separate tools for data prep, training, tracking, deployment, and monitoring. None talk to each other.
Duct-tape integrations break constantly.
The solution:
Start with integrated platforms when possible
Use open standards (like MLflow’s model format)
Build APIs between tools for proper integration
Don’t reinvent the wheel—use existing tools
Gradually consolidate as you mature
Pick tools that work together, not tools that are “best of breed” in isolation.
Challenge 5: Cost Management
The problem: Cloud bills skyrocket. GPU training runs 24/7. Storage costs explode with model versioning.
The solution:
Set up cost monitoring and alerts
Use spot instances for non-critical training
Implement auto-shutdown for idle resources
Archive old model versions to cheaper storage
Optimize models for inference efficiency
Track ML costs separately. They can quickly dwarf regular infrastructure costs.
Challenge 6: Regulatory Compliance and Governance
The problem: Healthcare, finance, and other regulated industries require explainability, auditability, and bias detection.
“The model works” isn’t enough.
The solution:
Implement model governance frameworks from day one
Log all training data, model versions, and predictions
Build explainability into model design
Set up bias detection in monitoring
Create audit trails for regulatory review
Use tools with built-in compliance features
Don’t treat compliance as an afterthought. Build it into your MLOps foundation.
The Future of MLOps: What’s Coming in 2025 and Beyond
MLOps is evolving fast. Here’s where things are headed:
Trend 1: LLMOps (Large Language Model Operations)
GPT, Claude, Gemini—large language models are everywhere. But operationalizing them is different from traditional ML.
LLMOps focuses on:
Prompt engineering pipelines
Fine-tuning workflows
Token cost optimization
Vector database management
Retrieval-Augmented Generation (RAG) monitoring
The MLOps market is projected to hit $11 billion by 2034 (from $1.7B in 2024), with LLMOps driving much of that growth.
Trend 2: Automated Retraining and Self-Healing Models
Models that detect their own drift and automatically retrain without human intervention.
Imagine: your model notices data drift, triggers retraining on fresh data, validates the new version, deploys it, and only alerts humans if something goes wrong.
This is already happening at companies like Amazon and Netflix.
Trend 3: Edge MLOps
Running ML models on devices (phones, IoT sensors, cars) instead of cloud servers.
Challenges:
Limited compute resources
No constant internet connection
Need for model compression
Over-the-air model updates
Tools are emerging specifically for edge MLOps—TensorFlow Lite, ONNX Runtime, and specialized frameworks.
Trend 4: MLOps + DevOps Convergence
The line between MLOps and DevOps is blurring.
Organizations are building unified platforms that handle both traditional software and ML models. Same CI/CD pipelines. Same monitoring tools. Same deployment processes.
This reduces complexity and improves collaboration.
Trend 5: Stronger Governance and Ethical AI
With regulations like the EU AI Act and Biden’s Executive Order on AI, governance is mandatory.
Expect:
Automated bias detection in monitoring
Explainability requirements for deployed models
Data provenance tracking
Model decision auditing
Fairness metrics alongside accuracy metrics
Ethical AI isn’t optional anymore.
Trend 6: Specialized MLOps for Verticals
Healthcare MLOps will look different from retail MLOps.
Industry-specific platforms are emerging with:
Pre-built compliance frameworks
Domain-specific feature stores
Vertical-optimized models
Industry standard integrations
Generic MLOps works, but specialized solutions will win in regulated industries.
The bottom line? MLOps is maturing from “nice to have” to “business critical”. Companies that master it will dominate their industries. Those that don’t will struggle to deploy AI at all.
Wrapping It All Up
Let’s bring this home.
MLOps isn’t just a buzzword—it’s the difference between AI that works and AI that fails. Building models is easy. Keeping them healthy in production? That’s the real challenge.
Remember the statistics:
67% of AI models never reach production
91% of deployed models degrade over time
$1.7 billion MLOps market growing to $11B by 2034
Your models need constant monitoring, just like patients need regular checkups. Data drifts. Concepts change. Performance degrades. Without MLOps, you’re flying blind.
The good news? You don’t need to build everything from scratch. Start small:
Pick an experiment tracking tool (MLflow is free)
Set up basic monitoring (Evidently AI is open-source)
Automate one thing (maybe deployment)
Add more automation gradually
Keep improving
Real companies—Netflix, Uber, Airbnb—prove MLOps works at scale. The tools exist. The best practices are documented.
What’s stopping you?
Start monitoring your models today. Because the only thing worse than not deploying AI is deploying AI that slowly stops working—and nobody notices until customers complain.
Your models need a doctor. MLOps is that doctor.
Now go give your AI the healthcare it deserves.
5 Unique FAQs About MLOps
Q1: Can I do MLOps without specialized tools, or do I need expensive platforms?
You can absolutely start with free open-source tools like MLflow, Evidently AI, and Apache Airflow. Many successful MLOps implementations begin with these free tools and only adopt paid platforms as they scale. Start small, prove value, then invest in enterprise tools if needed. The practices matter more than the tools.
Q2: How do I know when my model needs retraining?
Watch for three key signals: (1) Performance metrics dropping below your baseline threshold (e.g., accuracy falls from 95% to 92%), (2) Statistical drift in your input data exceeding acceptable limits, or (3) Business metrics declining (conversion rates, revenue, customer satisfaction). Set up automated monitoring to catch these early, and establish clear thresholds that trigger retraining workflows.
Q3: Is MLOps only for large companies with massive ML teams?
Not at all. Even solo data scientists benefit from basic MLOps practices. Start with simple automation—version your models, track experiments, monitor production performance. You don’t need a 50-person team. Cloud platforms like AWS SageMaker and Azure ML offer managed services that handle the infrastructure, letting small teams focus on models rather than operations.
Q4: What’s the difference between model monitoring and traditional application monitoring?
Traditional monitoring tracks system health—CPU, memory, latency, errors. Model monitoring adds ML-specific metrics like accuracy, drift detection, data quality, prediction distribution, and feature importance. You need both. A model can have perfect system health (fast responses, no errors) while producing terrible predictions because of data drift.
Q5: How often should I retrain my machine learning models?
There’s no one-size-fits-all answer. Some models need daily retraining (fraud detection, stock prediction), others quarterly (customer segmentation), and some only when performance degrades (image classification). Set up performance monitoring, run offline experiments to test different retraining frequencies, and let data—not assumptions—guide your schedule. Start conservatively and adjust based on observed drift rates.
Want to dive deeper into MLOps? Check out the keywords I compiled—195+ terms covering everything from MLOps platforms to model governance. Whether you’re researching tools, looking for best practices, or planning your MLOps career, these resources will get you started.
Ready to implement MLOps in your organization? Start with one model. Add monitoring. Track performance. Automate deployment. Build from there. The journey of a thousand models begins with monitoring just one.
Have questions or success stories about your MLOps journey? Drop them in the comments below. I’d love to hear what challenges you’ve faced and what solutions worked for you.


Pingback: The Ultimate (Machine Learning) ML Lifecycle: From Brilliant Idea to Seamless Deployment and Beyond - Bing Info