Implementing Responsible AI from Day One: A Comprehensive Framework for Building Trustworthy AI Systems
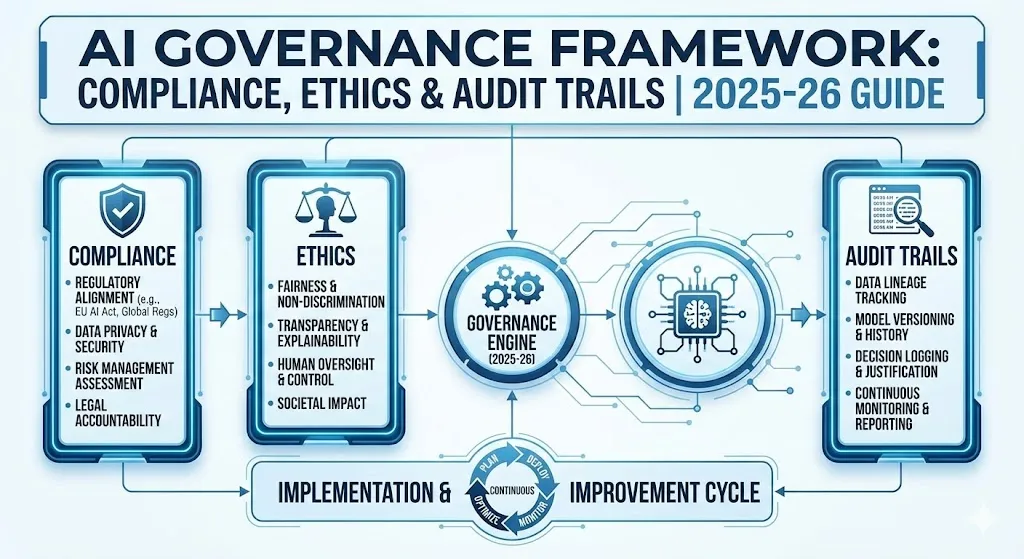
Implementing Responsible AI from Day One: A Comprehensive Framework for Building Trustworthy AI Systems A lot of companies want to employ AI solutions right soon, but they do it in a way that makes them uneasy: they build up AI systems first and then decide who is in control. We know this way of doing things is bad because it has cost us money, caused consumers lose faith in us, and gotten us in trouble with the police. The second choice is to employ AI properly from the beginning. This is the correct thing to do, and it also gives you an edge over your competition that speeds up deployment, decreases risk, and adds actual economic value. This shift is a huge step forward in how we construct AI. Smart organizations know that being responsible doesn’t stop them from moving forward. They don’t see it that way; they see it as the base for AI that will last and flourish. Building ethical AI from the bottom up can help you gain cleaner architectures, faster approvals, better alignment with stakeholders, and solutions that operate better in the real world. What does it mean for AI to be responsible? Not Just Following Orders Responsible AI includes creating, using, and running AI systems in ways that are in conformity with laws, morals, and social norms. It also means lowering the chance of getting hurt or having an accident. It’s not the same as compliance, although one possible outcome is compliance. When we talk about responsible AI, we mean that there are eight primary areas that work together to develop systems that people can trust: 1. Fairness Fairness makes guarantee that AI doesn’t make decisions that affect one group more than another. This entails looking at the training data to make sure it has a healthy mix of people from different backgrounds. It also requires utilizing statistical fairness criteria like demographic parity and equal opportunity, and evaluating models across different demographic groups on a regular basis to make sure they don’t discriminate. 2. Explainability Explainability is figuring out how AI systems make choices. Shapley values and LIME (Local Interpretable Model-agnostic Explanations) are two techniques to teach humans how AI makes choices. This provides them an opportunity to look over, fix, and make models better before they are used. 3. Privacy and Security Privacy and Security make ensuring that AI models and data are kept, used, and managed in the right way. This isn’t simply about writing code to save data. It also provides rules for who can access it, a safe place to keep models, and security from attacks that could destroy the system’s integrity. 4. Safety Safety is highly important when it comes to keeping people, communities, and the environment safe from things that shouldn’t happen. This involves having strong protections, comprehensive testing, rules for how to handle problems, and measures to make sure that people are in charge of making crucial decisions. 5. Human-in-the-Loop AI systems can make decisions that are far different from what people want. This keeps people in charge and stops AI from doing things that people can’t understand or control. 6. Veracity and Robustness Veracity and Robustness are adjectives that inform you how strong, accurate, and dependable a system is. This entails verifying sure the model is correct, dealing with edge circumstances, searching for model drift in production environments, and keeping an eye on performance to make sure it stays in line with what was planned. 7. Governance Governance makes sure that AI is produced and utilized in a way that is both legal and moral by setting rules, norms, and checks. Governance is anything that has to do with keeping records, making decisions, and addressing problems. 8. Transparency AI systems should be open about how they were built, where they acquired their data, how they work, and what they can and can’t do. When AI systems are open, people who care about them can choose whether or not to use them and how to do so. Key Takeaway: The Responsible AI Framework has eight basic parts. The Business Case for Responsibility: Why This Is Important Right Now We recognize that acting fast is vital. It’s really crucial to get goods to market promptly. Every day you wait could cost you money and offer your competitors an edge. Companies that apply ethical AI methods from the beginning, on the other hand, say they actually progress faster, not slower. They make better choices and have models that are ready for production and can be readily expanded. ROI and Performance Statistics The figures convey a powerful story. Companies who adopt advanced responsible AI methods claim they get a lot out of them: Benefit Category Percentage of Companies Reporting Gain Innovation & New Ideas 81% Efficiency & Less Rework 79% Worker Satisfaction 56% System Reliability & Customer Experience 55% Market Growth & Sales 54% Compliance Cost Savings 48% The most significant point is that research from the MIT Sloan Management Review and the Boston Consulting Group reveals that organizations who employ AI properly are three times more likely to see big benefits. those who have effective responsible AI governance say their profits have increased compared to those that don’t have it. It’s easy to understand how the ROI works: To avoid fees, you need to remain out of trouble with the law. The EU AI Act says that fines might be as high as €35 million or 7% of a company’s global yearly revenues. It also keeps you from having to recall models, go to court, or deal with problems at work. When systems are ready for an audit, it’s easier to make adjustments swiftly. This speeds things up and lowers the amount of rework, failures, and technical debt. Time-to-Market Acceleration speeds up deployment by cutting down on the number of approval loops, getting everyone on the same page faster, and making sure systems are ready for governance from the start. Brand and Trust Capital keep your business robust and